Benchmark de bibliothèques data 2025 : Pourquoi j'ai lâché Pandas pour Polars (Le test du CSV de 4 Go)
Benchmark de bibliothèques data 2025 : Pourquoi j'ai lâché Pandas pour Polars (Le test du CSV de 4 Go)

DuckDb, Pyspark, Pandas, Polars que choisir ?
On voit encore beaucoup de monde utiliser Pandas par défaut aujourd'hui. C'est un réflexe : on a de la data, on import pandas. Mais est-ce qu'en 2025, c'est toujours le meilleur choix ?
Nous sommes entrés dans l'ère du "Small Big Data".
Le paradoxe est simple : on a de plus en plus de données, mais on travaille souvent sur des "petits PC" (laptops pro, instances cloud standard). On arrive fatalement à un goulot d'étranglement : les machines saturent. On a besoin de puissance et d'optimisation pour ne pas gaspiller nos ressources.
Pandas est facile d'accès, mais il traîne des boulets historiques : il est "monothread" et très gourmand en mémoire. J'ai donc voulu comparer les alternatives modernes pour voir si on n'avait pas intérêt à regarder ailleurs.
1. Le Protocole du Test
Pour ce benchmark, j'ai utilisé ma machine personnelle, une config solide mais réaliste :
CPU : AMD Ryzen 5 5600x (12 threads, 6 cœurs physiques)
RAM : 64 Go (c'est confortable, mais vous allez voir que c'était nécessaire !)
Le Fichier : Le fichier SIRENE des entreprises françaises — un bon gros CSV de 3.8 Go avec 28 millions de lignes et 35 colonnes
Les Cas d'usage :
Conversion "Bronze vers Silver" : lecture du CSV brut → écriture en Parquet
Requêtage : recherche d'un SIREN spécifique (CSV vs Parquet)
Écriture massive : export de 10 millions de lignes en CSV et Parquet
Les 4 combattants :
Pandas — Le standard historique
Polars — Le challenger Rust
PySpark — Le poids lourd distribué
DuckDB — L'outsider SQL
Le code utilisé pour effectuer ce benchmark est disponible dans ce repo Git. Vous pouvez lancer le test à partir d'un notebook après avoir préalablement modifié votre fichier .env pour coller à votre configuration et à vos fichiers de test.
2. Benchmark Conversion CSV → Parquet
J'ai lancé la conversion sur les quatre bibliothèques.
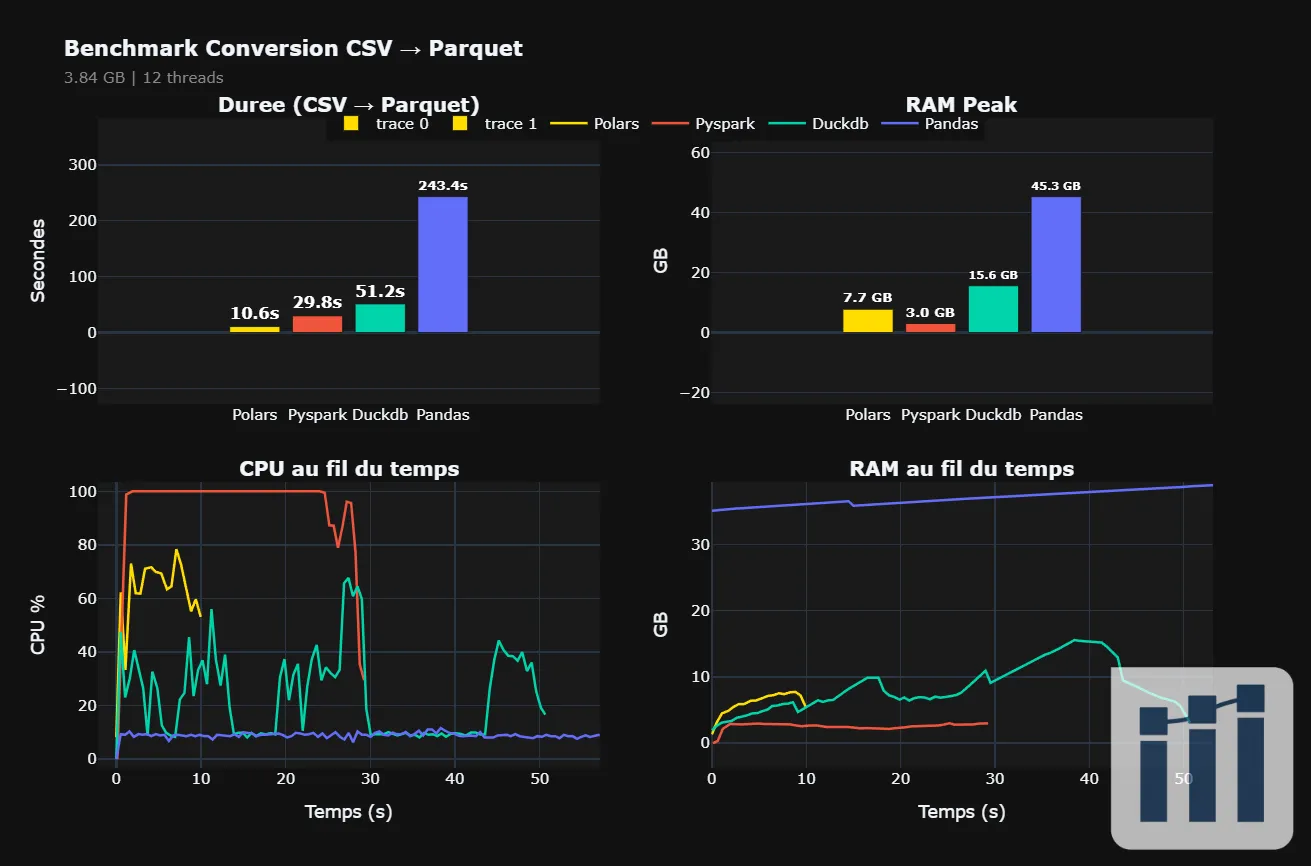
Voici les résultats :
Bibliothèque | Durée | CPU avg | RAM max | Ratio |
|---|---|---|---|---|
Polars | 9.1s | 65.9% | 8.0 GB | 1x |
PySpark | 29.4s | 95.0% | 5.7 GB | 3.2x |
DuckDB | 52.3s | 23.5% | 14.9 GB | 5.7x |
Pandas | 224.9s | 8.8% | 49.7 GB | 24.6x |
3. Analyse : Pourquoi de tels écarts ?
Pandas : Le goulot d'étranglement (225s)
Le résultat est sans appel : 25 fois plus lent que Polars.
Pourquoi ?
Single-threaded : Avec 8.8% de CPU, Pandas n'utilise qu'un seul cœur. Sur une machine 12 threads, c'est du gâchis de puissance.
Explosion de la RAM : C'est le point critique. Pour traiter un fichier de 3.8 Go, Pandas a consommé 50 Go de RAM. Il fait énormément de copies en mémoire.
Le danger : Si j'avais eu une machine standard de 16 Go de RAM, le script aurait crashé avec un beau MemoryError. Pas top en prod.
Polars : La victoire de l'architecture moderne (9s)
Polars plie l'affaire en moins de 10 secondes. C'est une bibliothèque écrite en Rust, conçue dès le départ pour le parallélisme.
CPU à 66% : Il utilise efficacement tous les cœurs disponibles.
Zéro Copie : Grâce au format mémoire Apache Arrow, il évite les duplications. Résultat : il consomme 6x moins de RAM que Pandas (8 Go vs 50 Go).
Et côté code ? C'est quasiment la même syntaxe :
Python
# Pandas
df = pd.read_csv("data.csv")
df.to_parquet("output.parquet")
# Polars (mode lazy, encore plus efficace)
pl.scan_csv("data.csv").sink_parquet("output.parquet")
Pas d'excuse pour ne pas migrer.
PySpark : Le moteur Diesel (29s)
Spark met 29 secondes. En creusant les logs, j'ai mesuré que ~3 secondes sont consommées juste pour démarrer la JVM. Le traitement réel prend environ 26 secondes.
C'est un peu lourd au démarrage, comme un diesel. Mais une fois lancé, c'est robuste et ça scale à l'infini.
Fait intéressant : PySpark affiche la consommation RAM la plus basse (5.7 Go) car il traite les données en streaming sans tout charger en mémoire. Le CPU à 95% montre qu'il exploite à fond la machine.
Spark, c'est une techno taillée pour les clusters. Un peu "too much" pour du local, mais imbattable quand vos données dépassent ce qu'une seule machine peut gérer.
DuckDB : L'alternative SQL (52s)
Une très bonne alternative "In-Process" et une très belle découverte pour moi, je ne connaissais pas cette bibliothèque avant de faire mes recherches pour ce benchmark. Si vous êtes plus à l'aise avec le SQL qu'avec les DataFrames, DuckDB fait le job très honnêtement :
SQL
COPY (SELECT * FROM read_csv('data.csv'))
TO 'output.parquet' (FORMAT 'PARQUET')
Pas d'infrastructure lourde, pas de cluster à gérer. Simple et efficace.
4. Benchmark Requêtage : CSV vs Parquet
C'est bien beau de convertir en Parquet, mais est-ce que ça vaut vraiment le coup pour les requêtes ? J'ai testé une recherche simple : trouver toutes les lignes correspondant à un SIREN spécifique.
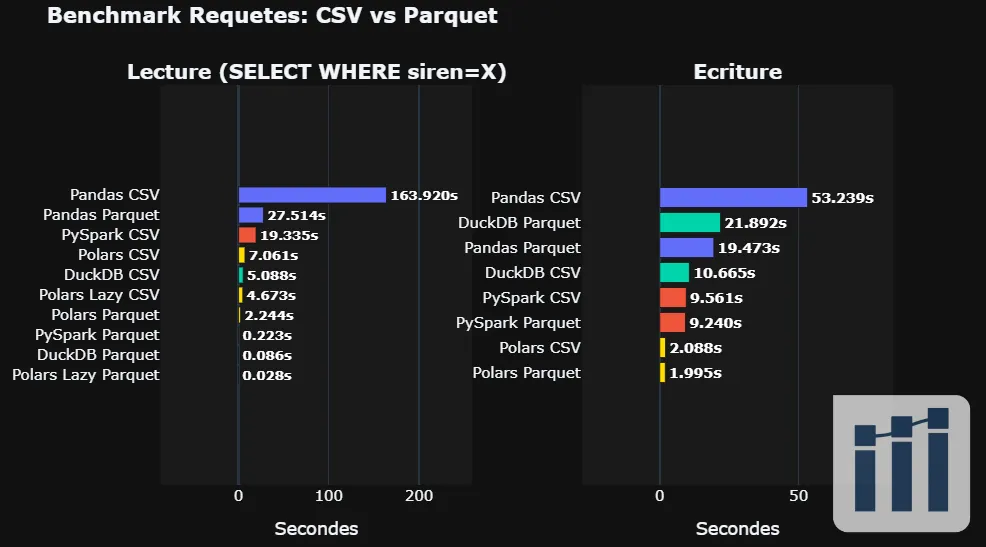
Les résultats en lecture
Méthode | Durée | Ratio |
|---|---|---|
Polars Lazy Parquet | 0.028s | 1x |
DuckDB Parquet | 0.086s | 3.1x |
PySpark Parquet | 0.223s | 8.1x |
Polars Parquet | 2.24s | 81x |
Polars Lazy CSV | 4.67s | 169x |
DuckDB CSV | 5.09s | 184x |
Polars CSV | 7.06s | 255x |
PySpark CSV | 19.34s | 699x |
Pandas Parquet | 27.51s | 995x |
Pandas CSV | 163.92s | 5930x |
L'effet "Predicate Pushdown"
Le grand gagnant ? Polars Lazy + Parquet avec 28 millisecondes. C'est 6000 fois plus rapide que Pandas CSV.
Comment c'est possible ? Le secret s'appelle le Predicate Pushdown.
Quand vous faites :
# Polars Lazy - le filtre est "poussé" dans la lecture
result = pl.scan_parquet("data.parquet").filter(pl.col("siren") == 920900271).collect()
Polars ne charge pas les 28 millions de lignes. Il lit les métadonnées du Parquet, identifie les "row groups" qui peuvent contenir le SIREN recherché, et ne lit que ceux-là. C'est de la chirurgie.
À l'inverse, Pandas CSV doit :
Lire tout le fichier (3.8 Go)
Parser chaque ligne
Charger en RAM
Puis seulement filtrer
C'est comme vider une piscine pour trouver une balle de tennis (bon en vrai elle va flotter mais vous avez compris).
DuckDB : Le SQL rapide
DuckDB fait aussi du Predicate Pushdown nativement. En 86 ms, il rivalise avec Polars. Pour ceux qui préfèrent le SQL, c'est la solution idéale :
SELECT * FROM read_parquet('data.parquet') WHERE siren = 920900271
5. Benchmark Écriture : 10 Millions de Lignes
Dernier "jeu" : l'écriture. J'ai pris 10 millions de lignes et demandé à chaque bibliothèque de les exporter en CSV et en Parquet.
Les résultats en écriture
Méthode | Durée | Ratio |
|---|---|---|
Polars Parquet | 2.0s | 1.0x |
Polars CSV | 2.1s | 1.0x |
PySpark Parquet | 9.2s | 4.6x |
PySpark CSV | 9.6s | 4.8x |
DuckDB CSV | 10.7s | 5.3x |
Pandas Parquet | 19.5s | 9.8x |
DuckDB Parquet | 21.9s | 11.0x |
Pandas CSV | 53.2s | 26.7x |
Polars domine encore
2 secondes pour écrire 10 millions de lignes en Parquet. Polars est une machine de guerre.
Ce qui est intéressant :
Polars est aussi rapide en CSV qu'en Parquet (≈2s)
PySpark est régulier (≈9s) peu importe le format — la JVM lisse tout
Pandas CSV souffre énormément (53s) car il sérialise ligne par ligne
DuckDB Parquet est étonnamment lent ici (22s), probablement à cause de la compression
Le ratio CSV/Parquet
Pour Pandas, écrire en Parquet est 2.7x plus rapide qu'en CSV. C'est contre-intuitif (Parquet est compressé !), mais ça s'explique : Parquet utilise un format colonne binaire, tandis que CSV demande de convertir chaque valeur en texte.
6. Récapitulatif : Le Tableau Final
Cas d'usage | 🥇 Premier | 🥈 Second | 🥉 Troisième | 💀 Dernier |
|---|---|---|---|---|
Conversion CSV→Parquet | Polars (9s) | PySpark (29s) | DuckDB (52s) | Pandas (225s) |
Lecture Parquet | Polars Lazy (0.03s) | DuckDB (0.09s) | PySpark (0.22s) | Pandas (28s) |
Lecture CSV | Polars Lazy (4.7s) | DuckDB (5.1s) | Polars (7.1s) | Pandas (164s) |
Écriture Parquet | Polars (2.0s) | PySpark (9.2s) | Pandas (19.5s) | DuckDB (22s) |
Écriture CSV | Polars (2.1s) | PySpark (9.6s) | DuckDB (10.7s) | Pandas (53s) |
7. Conclusion : FinOps et choix technologiques
Il n'y a pas de mauvais outils, il y a de mauvais usages.
Pour l'exploration rapide / POC : Pandas reste très bien. L'écosystème est immense (fonctions natives Snowflake, Databricks, Fabric, etc.) et c'est le standard des éditeurs.
Pour le Big Data distribué (téraoctets) : Spark reste le roi. Si vos données ne tiennent pas sur une machine, ne bricolez pas, prenez Spark. Attention cependant à la complexité (les logs sont illisibles pour les débutants) et au coût des clusters peut être choquant pour certains.
Pour du SQL pur sans infrastructure : DuckDB est excellent. Performance solide, syntaxe familière, zéro config.
Mais pour l'ETL local et le "Small Big Data" : Polars est le nouveau roi.
Et il y a un argument FinOps qu'on ne peut pas ignorer :
Si vous faites tourner ce traitement dans le Cloud (AWS Lambda, Azure Functions, Databricks), Polars tourne 25x plus vite que Pandas pour la conversion, et 27x plus vite pour l'écriture.
Sur la facture à la fin du mois, c'est potentiellement 25x moins de temps de compute facturé. Ça parle aux décideurs, ça.
Et côté requêtage ? 6000x plus rapide avec le bon combo (Polars Lazy + Parquet). Ce n'est plus de l'optimisation, c'est un changement de paradigme.
Alors, pour vos pipelines de données en 2025, arrêtez de payer pour attendre que Pandas finisse ses copies : passez à Polars.