Comprendre l'architecture des LLMs en 2025 et Dominer le GEO
GPT-5.2, Gemini 3 Pro, Claude Opus 4.5 : mais au-delà de la hype, comment ces modèles d'intelligence artificielle fonctionnent-ils?
En 2025, l'adoption de l'IA générative n'est plus une option, c'est un standard obligatoire. Les modèles comme GPT-5.2, Gemini 3 ou Claude Opus 4.5 atteignent des niveaux de raisonnement quasi-humains, un fossé se creuse. D'un côté, les entreprises qui "jouent" avec des prompts ; de l'autre, celles qui en maîtrisent l'architecture et le fonctionnement pour créer de la valeur.
Pour exister sur les nouveaux moteurs de recherche (Google AI Overviews, SearchGPT, Comet), il ne suffit plus de faire du SEO à l'ancienne. Il faut dès à présent entrer dans l'ère du GEO (Generative Engine Optimization) : entre autres, structurer sa donnée pour qu'elle soit comprise, ingérée et citée par les algorithmes .
La performance selon nous chez Liiink, naît de la compréhension technique.
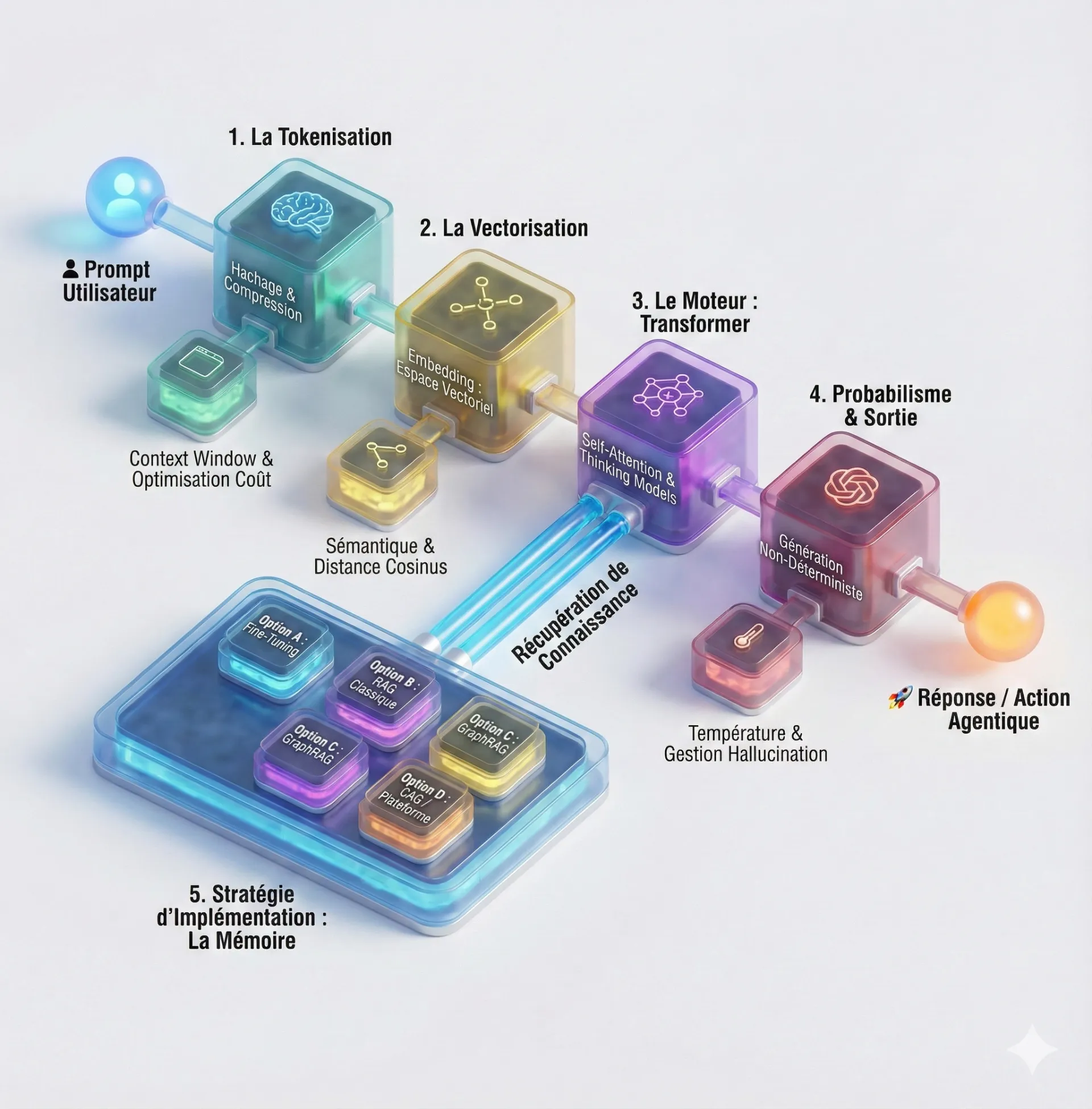
Décryptons le chemin d'une requête faite à un LLM en 5 fondamentaux.
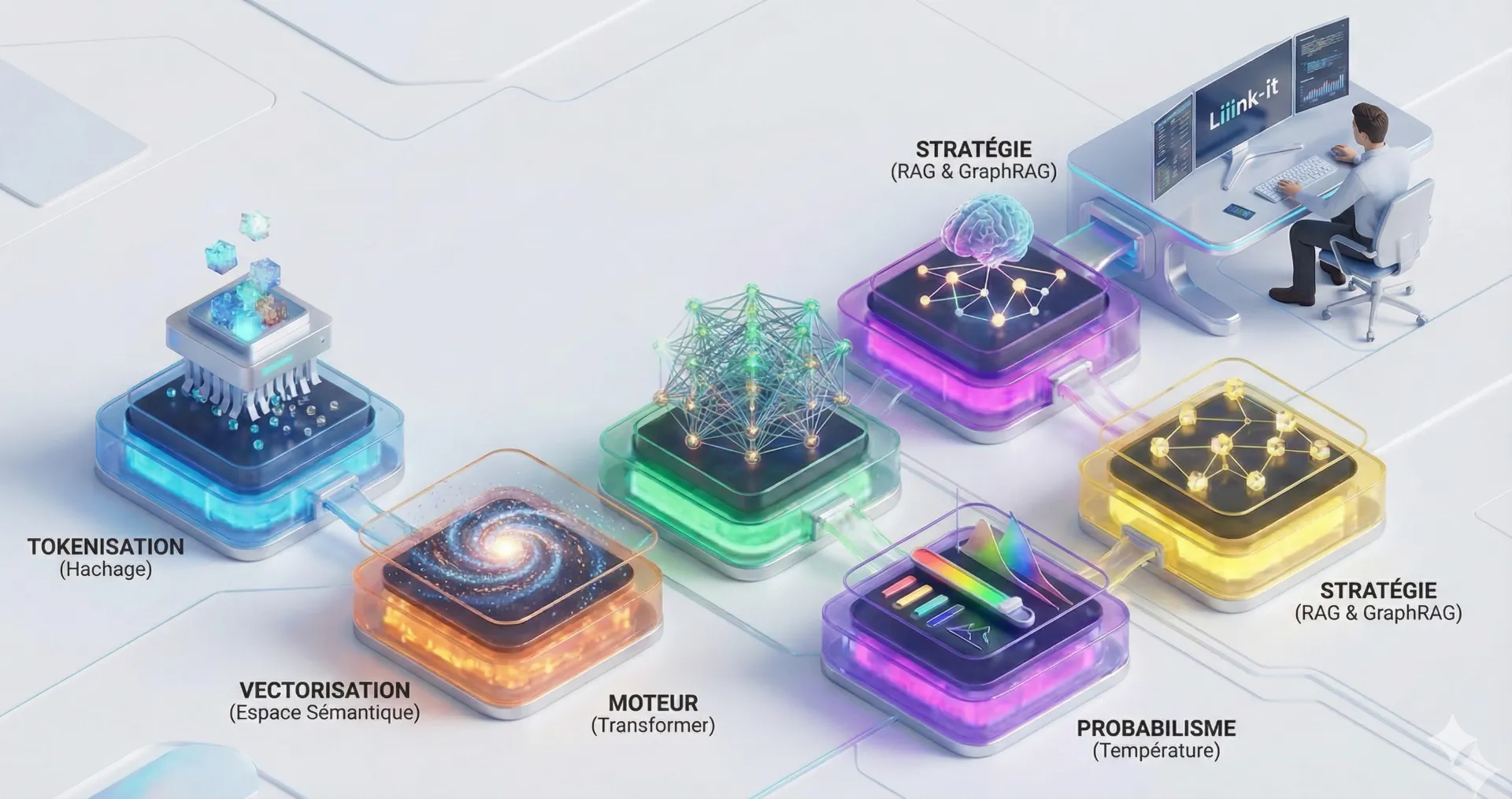
1. La Tokenisation : L'unité de compte de l'économie IA
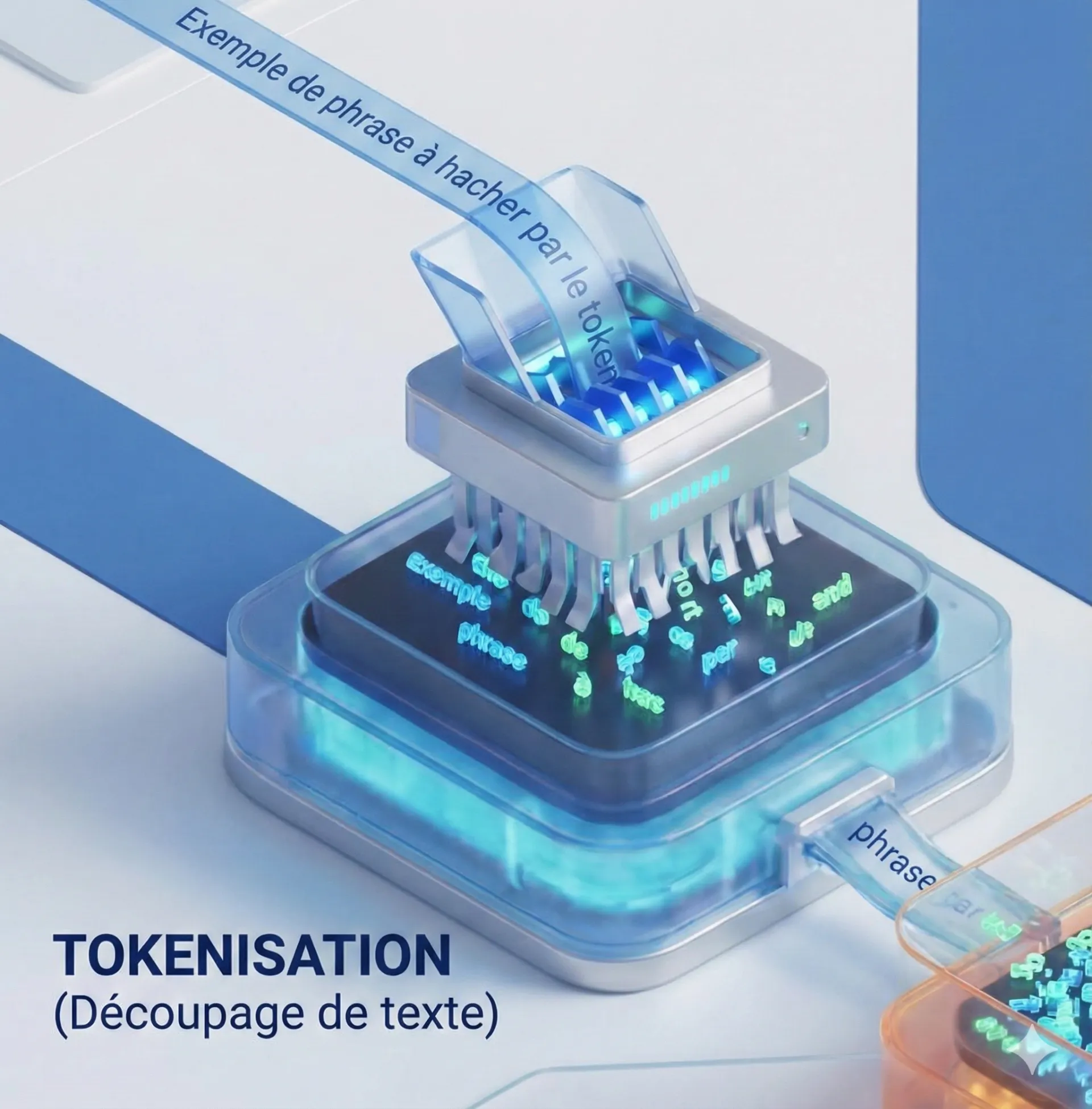
La première illusion est de croire que Gemini 3 Pro ou Llama 4 lisent votre texte. En réalité, un modèle de langage est aveugle aux mots. Il ne voit que des Tokens.
Le Concept Technique
Avant d'entrer dans le réseau de neurones, votre prompt est "haché" par un Tokenizer.
La règle d'or : 1 token \approx 0,75 mot (en anglais).
L'évolution 2025 : Les modèles récents optimisent cette compression. Un mot complexe technique n'est plus brisé en 5 morceaux, mais reconnu comme une entité unique grâce à des vocabulaires plus élaborés.
L'Impact Business & Coûts
Pourquoi est-ce important pour votre architecture?
Le coût : Les API facturent au million de tokens. Une mauvaise ingénierie de prompt sur un modèle coûteux comme Claude Opus 4.5 peut tripler votre facture cloud (Et encore plus sur un modèle de type “thinking”).
La Fenêtre de Contexte (Context Window) : Avec Gemini 3 Pro atteignant une fenêtre de 1 million de tokens, on peut théoriquement lui donner "toute ou bonne partie de la mémoire de l'entreprise". Mais il faut faire très attention : saturer le contexte réduit la précision (le phénomène “Lost in the Middle") et entraîne à la perte d'information. La technique ici pour toujours avoir des réponses pertinentes, consiste à ne fournir que les tokens utiles.
2. La Vectorisation (Embeddings)
Une fois “tokenisée”, comment le modèle comprend-il le sens? Il transforme ces tokens en coordonnées numériques dans un espace multidimensionnel (Vector Space). C'est la Vectorisation.
Le Mécanisme
Bien que difficile, tenter d'imaginer un graphique en milliers de dimensions. Chaque concept est un point.
Les vecteurs "Pomme de terre" et "Frites" sont mathématiquement proches.
Dans l'espace vectoriel d'un modèle 2025, la nuance entre "Code Java" et "Java (l'île)" est déterminée par la distance cosinus (qui mesure l'angle entre les vecteurs pour évaluer leur similarité sémantique) avec les mots aux alentours? Plus l'angle est grand, plus les vecteurs sont éloignés, et donc moins les concepts sont similaires sémantiquement.
C'est le secret de la recherche sémantique moderne. Google ne cherche plus vos mots-clés exacts, il cherche vos vecteurs. Pour ranker en 2025, votre contenu doit couvrir tout le "champ vectoriel" d'un sujet pour établir votre autorité (E-E-A-T).
3. Le Moteur : Transformer et "Thinking Models"
Si l'IA progresse de façon fulgurante, c'est grâce à l'architecture Transformer (Le fameux “T” dans GPT) et son mécanisme d'Auto-Attention (Self-Attention) .
L'Attention : La fin de l'oubli
Contrairement aux anciens réseaux qui lisaient un mot après l'autre, le Transformer lit toute la phrase simultanément.
Dans la phrase "Le serveur a crashé car il était surchargé", le mécanisme d'attention lie mathématiquement "il" à "serveur" avec une probabilité élevée.
Les modèles de 2025 comme GPT-5.2 multiplient ces "têtes d'attention" pour comprendre des nuances culturelles, techniques et émotionnelles simultanément.
La Nouveauté : Les modèles avec "Thinking"
Des modèles comme Claude 4.5 Opus Thinking ou Qwen-Thinking introduisent une étape de "réflexion" avant de répondre. Ils génèrent des "chaînes de pensée" sous forme d’un plan structuré ou les modèles se questionnent et progressent étape par étape pour vérifier leurs propres erreurs avant de produire le token final. Pour des tâches critiques (finance, code, RAG), c'est une révolution de fiabilité.
4. Probabilisme et Température : Gérer l'Hallucination
L'IA ne "sait" rien. Elle prédit le token suivant avec une probabilité statistique. C'est un système non-déterministe.
La Température : Un paramètre crucial
C'est le levier de contrôle principal de vos API :
Température 0.1 (Déterministe) : Le modèle choisit toujours le token le plus probable. Indispensable pour le codage ou l'extraction de données JSON.
Température 0.9 (Créatif) : Le modèle prend des risques. Utile pour le brainstorming marketing, la génération d’images ou d’histoires.
Le risque d'Hallucination : Même les modèles récents comme Grok 4.1 ou Gemini 3 peuvent halluciner si la température est mal réglée ou si les données sources manquent.
5. Stratégie d'implémentation : RAG, GraphRAG ou Fine-Tuning?
C'est la question que se pose toute personne ayant des besoins spécifiques IA. Comment connecter l'IA à nos données privées?
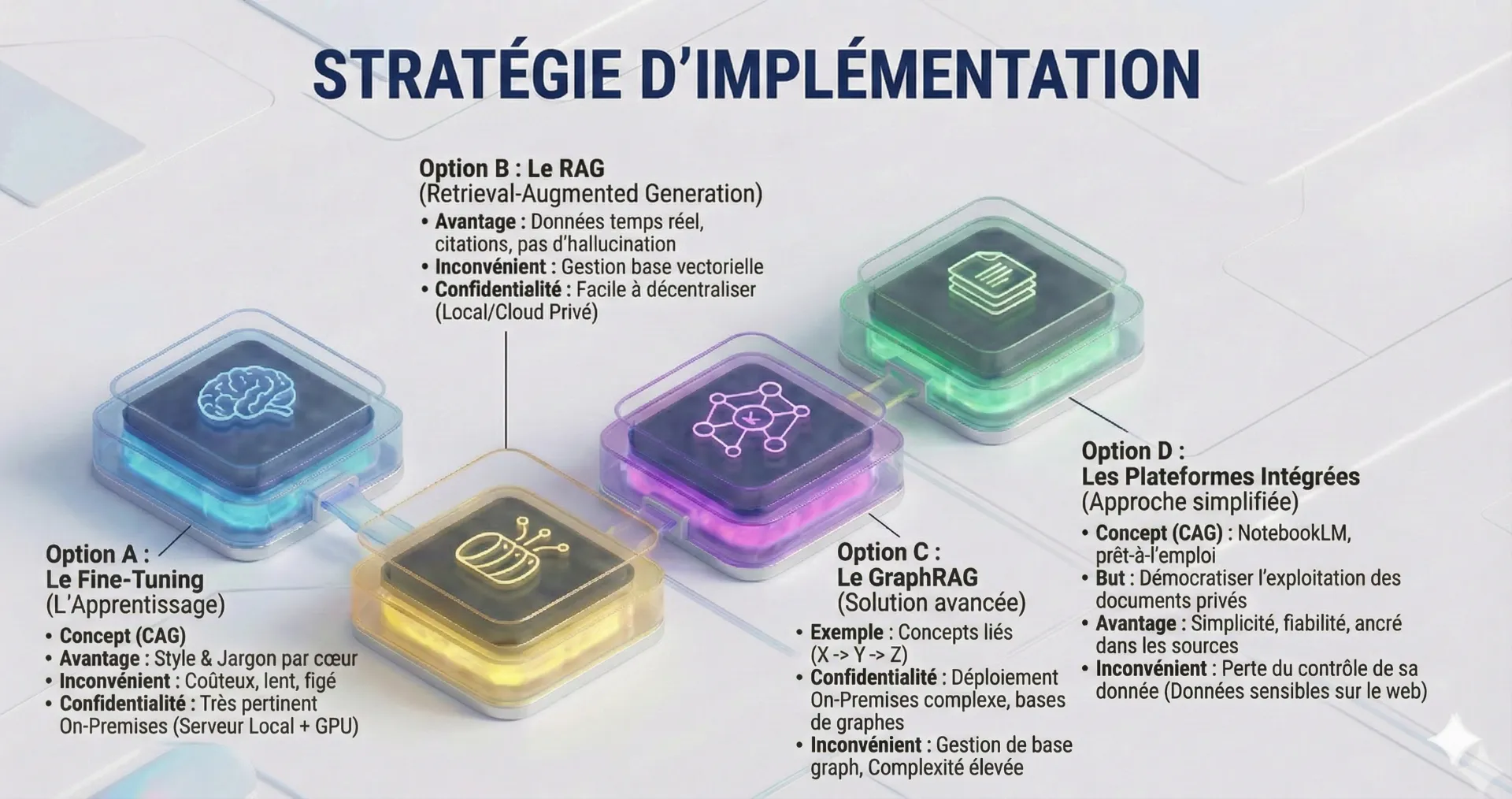
Option A : Le Fine-Tuning (L'Apprentissage)
On réentraîne Llama 4, Mistral ou Deep seek avec vos données.
Avantage : Le modèle apprend votre "style" et votre jargon par cœur.
Inconvénient : Coûteux, lent, et les connaissances sont figées à la date de l'entraînement.
Confidentialité et Local : Très pertinent pour le On-Premises. Une fois le modèle fine-tuné, il peut être déployé sur un serveur local équipé d'un GPU (souvent avec des modèles open-source plus petits comme Llama ou Mistral). Cela garantit que les données d'entreprise ne quittent jamais le réseau interne, offrant le plus haut niveau de confidentialité, même si cela demande une gestion matérielle (GPU) et logicielle plus lourde.
Option B : Le RAG (Retrieval-Augmented Generation)
L'architecture dominante en 2025. On connecte le modèle à une base vectorielle (Vector Database) qui contient vos documents à jour.
Avantage : Données temps réel, citations des sources, pas d'hallucination.
Inconvénient : Nécessite une gestion de la base vectorielle et une bonne chunking (découpage du texte) pour l'efficacité.
Confidentialité et Local : Facile à décentraliser. L'ensemble de la chaîne (LLM + Vector Database) peut être déployé en local (sur site) ou dans un cloud privé. Le modèle (LLM) peut être un modèle open-source léger exécuté sur un GPU local, tandis que la base vectorielle contenant les documents privés reste strictement en interne. C'est l'approche privilégiée pour les PME et grandes entreprises qui veulent la fiabilité du RAG sans exposer leurs données.
Option C : Le GraphRAG (Solution avancée)
C’est certainement une évolution majeure du RAG. Au lieu de simples vecteurs, on utilise un Knowledge Graph (Graphe de Connaissance) pour lier les concepts entre eux.
Exemple : Si vous demandez "Quel est l'impact de la mise à jour X?", le GraphRAG comprend que X est lié au module Y, qui est géré par l'équipe Z, et fournit une réponse systémique.
Confidentialité et Local : Déploiement On-Premises possible, mais plus complexe. L'architecture GraphRAG est une surcouche de l'architecture RAG. Elle est donc théoriquement déployable en local avec un GPU, mais nécessite des bases de données spécifiques (bases de données de graphes) et un effort d'ingénierie supplémentaire pour maintenir et mettre à jour le Knowledge Graph en interne. L'avantage de confidentialité est le même que pour le RAG : les données restent derrière le pare-feu de l'entreprise.
Option D : Les Plateformes Intégrées (Approche simplifiée du RAG)
Une alternative, pertinente pour les utilisateurs non-développeurs ou les équipes souhaitant exploiter rapidement leurs connaissances, est l'utilisation d'outils comme NotebookLM (ou d'autres solutions d'entreprise similaires).
Le Concept (qu’on appelle “CAG” pour Contextualized Augmented Generation) :
Plutôt que de construire l'architecture plus ou moins complexe RAG soi-même (base vectorielle, connecteurs, etc.), ces plateformes simplifient le processus. Elles permettent à l'utilisateur de lier directement l'IA à ses propres documents (Docs, PDF, notes, etc.) pour des réponses qui sont rigoureusement ancrées et citent ces sources spécifiques. C'est une forme de RAG "prête à l'emploi".Le But et l'Avantage :
L'objectif est de démocratiser l'exploitation des documents privés. L'IA ne puise pas dans sa connaissance générale (ou n'hallucine pas) mais répond uniquement en se basant sur le corpus de documents fourni par l'utilisateur. Cela offre :Simplicité : Pas de gestion d'API, de tokenization ou de vectorisation manuelle.
Fiabilité : L'IA est systématiquement ancrée dans les sources de vérité de l'entreprise ou de l'utilisateur.
Notre conviction : Pour 90% des cas d'usage business simples (Q&A sur documents, résumé, etc.), une approche de type CAG/Plateformes Intégrées (comme NotebookLM) est l'option la plus simple, fiable et au meilleur ROI. L'architecture RAG (voire agentic RAG : des agents autonomes capables de chercher l'info eux-mêmes en formulant des requêtes optimisées) sur des modèles comme Claude 4.5 Sonnet devient pertinente pour les 10% de cas d'usage nécessitant une intégration complexe (API sur bases de données multiples, gestion de bases vectorielles avancées, orchestration d'agents, volumétrie importante).
En conclusion : De la Génération à l'Action Agentique
Comprendre ces briques fondamentales (Token, Vecteur, Attention, RAG) n'est plus une simple curiosité technique; c'est la condition sine qua non pour dominer l'ère du GEO (Generative Engine Optimization) et créer une véritable valeur. L'année 2025 marque un pivot : le passage de l'IA purement générative (qui écrit du texte) à l'IA Agentique qui raisonne, planifie et exécute des tâches complexes.
Pour la majorité des cas d'usage business, l'approche simplifiée CAG/Plateformes Intégrées offre la voie la plus rapide et la plus fiable pour exploiter vos documents, surpassant les complexités d'un RAG classique. Cependant, quelle que soit la sophistication de l'architecture choisie (RAG, GraphRAG, CAG), n'oubliez jamais la règle d'or : la performance de l'IA, sa fiabilité et la pertinence de ses actions dépendront toujours de la qualité de votre requête et, surtout, de la rigueur de vos données sources.
L'IA ne frappe pas à la porte de vos entreprises ; elle y est déjà, et en maîtriser l'architecture est désormais l'avantage compétitif décisif.