Migrer un Azure Synapse Dedicated SQL Pool vers Microsoft Fabric Warehouse via DACPAC
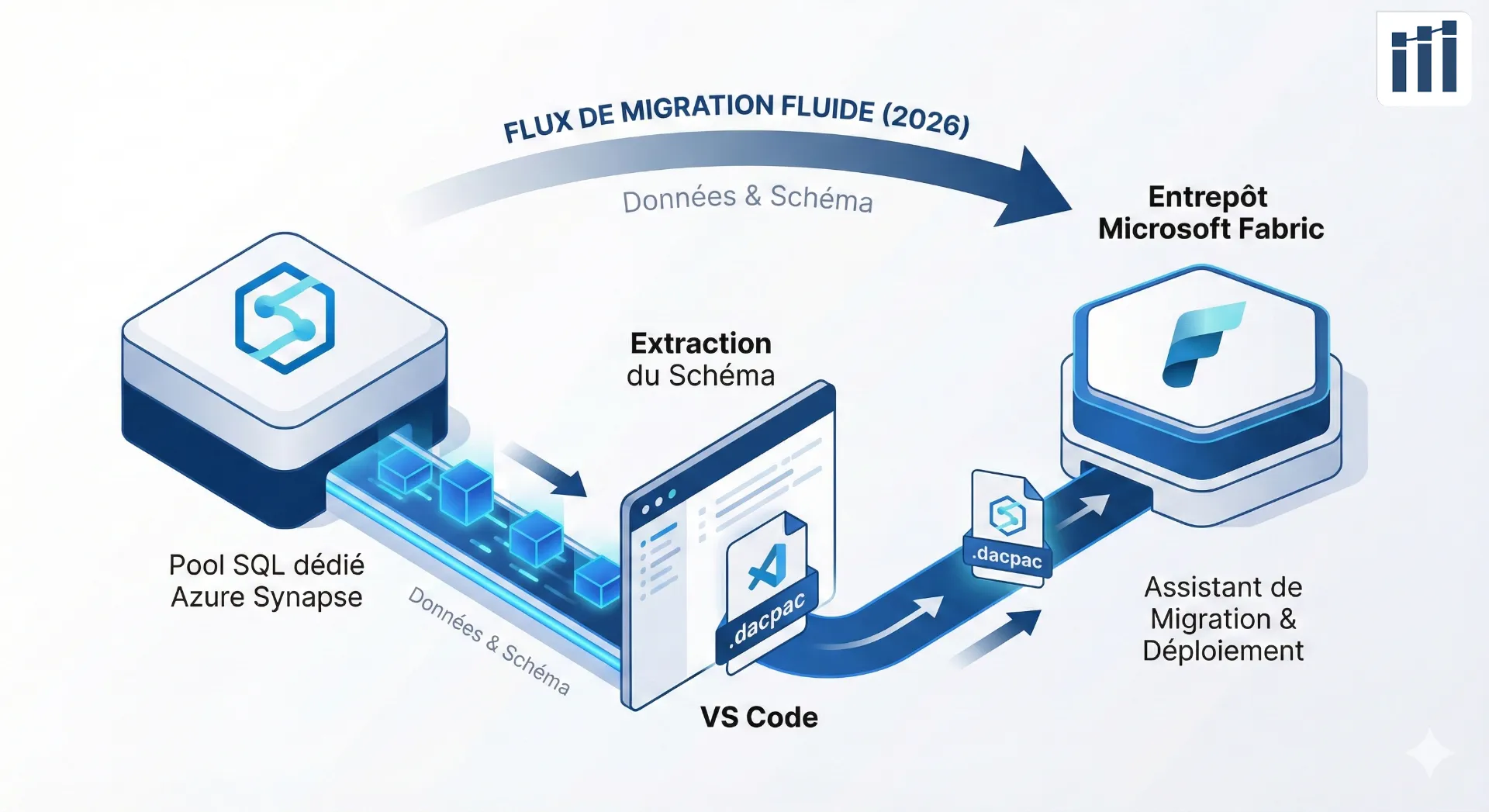
En 2026, voici comment migrer un Azure Synapse Dedicated SQL Pool vers Microsoft Fabric Warehouse via DACPAC
La migration d'un pool dédié Synapse vers un Warehouse Fabric n'a jamais été aussi accessible (j'en parle également dans mon article précédent). Microsoft a considérablement amélioré son Migration Assistant, et aujourd'hui, je vous guide pas à pas dans cette transition en utilisant l'approche DACPAC.
Prérequis
Avant de commencer, assurez-vous d'avoir installé les extensions suivantes dans VS Code :
Azure Tools : La boîte à outils Azure pour VS Code
VS CODE : Extension Azure Tools SQL Server (mssql) : Pour vous connecter aux bases de données SQL
SQL Database Projects : Pour créer et gérer les projets de base de données
📚 Ressources : SQL Database Projects | Azure Tools | SQL Server(mssql)
Étape 1 : Créer un projet de base de données
Rendez-vous dans la partie Database Projects de VS Code.
Cliquez sur Create new
Sélectionnez Azure SQL Database comme type de projet
Choisissez le nom et ensuite le répertoire où vous souhaitez créer votre projet
Sélectionnez Azure Synapse SQL Pool comme type de base de données
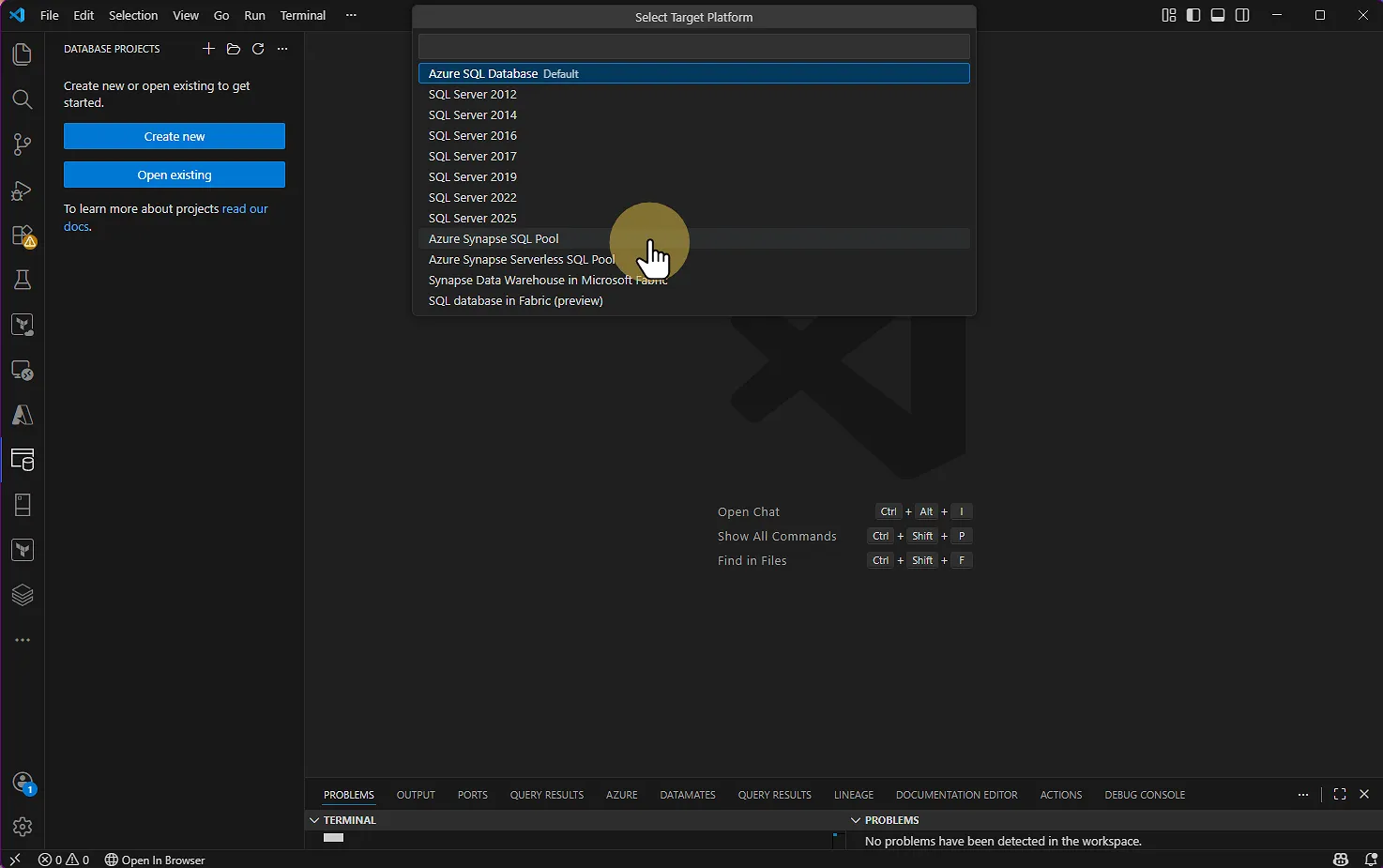
VS CODE : Database projects > Create New > Azure Synapse SQL Pool Répondez YES lorsqu'on vous demande si vous souhaitez utiliser le format SDK
Vous obtenez alors un projet de base de données vide, prêt à recevoir votre schéma.
Étape 2 : Importer le schéma depuis Synapse
C'est là que la magie opère. Il va falloir récupérer le schéma de votre base de données Synapse.
Faites un clic droit sur votre projet et sélectionnez Update Project from Database
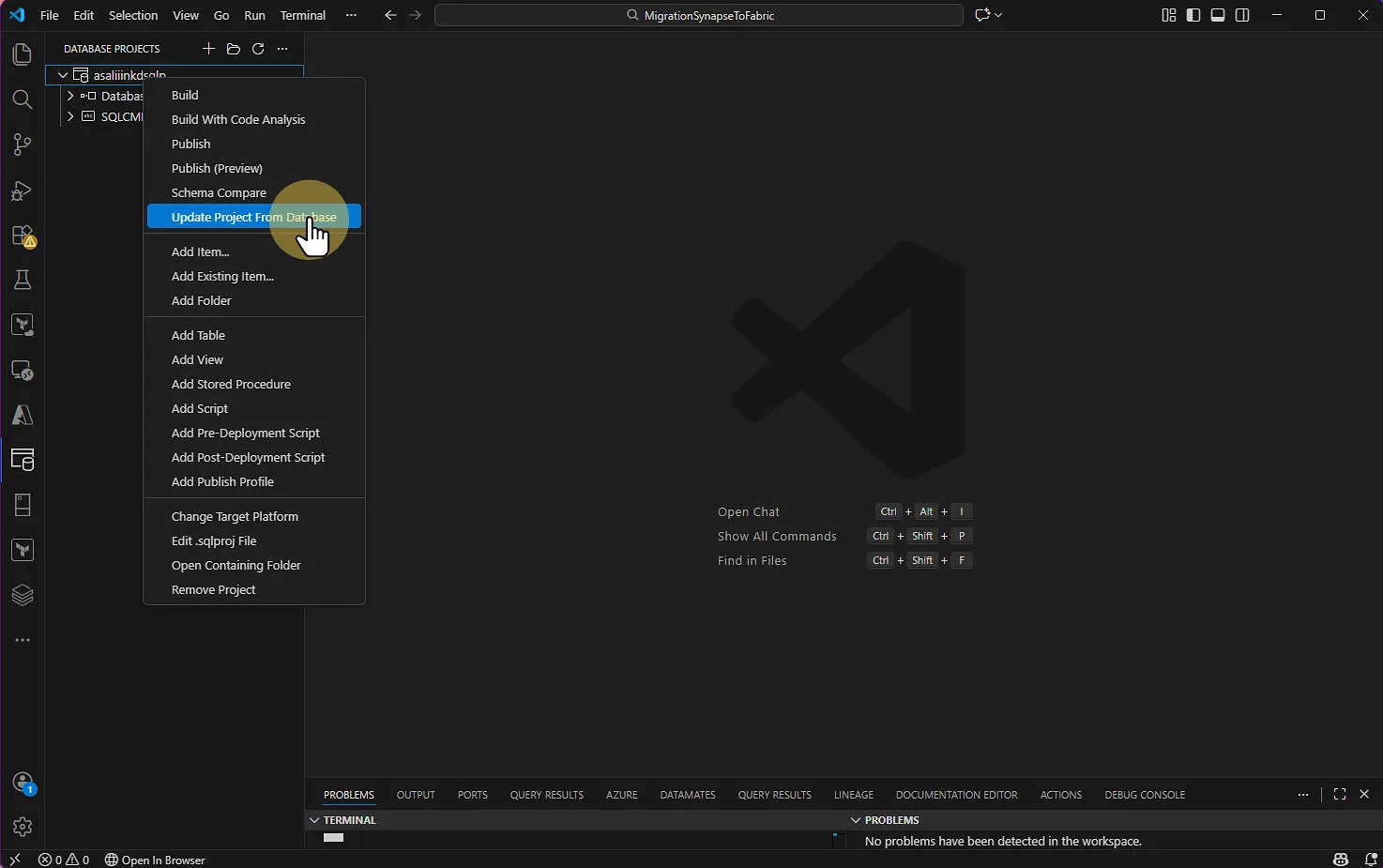
VS CODE : Database projects > Projet > Update Project From Database Sélectionnez votre base de données Synapse sur Azure (si vous avez déjà créé votre connexion)
Si la connexion n'a pas été créée au préalable dans VS Code, vous devrez la configurer :
Chaîne de connexion : Le nom de votre serveur Synapse (ex:
monserveur.sql.azuresynapse.net)Type d'authentification : MFA, compte SQL Server, Azure AD...
Base de données : Le nom de votre pool dédié
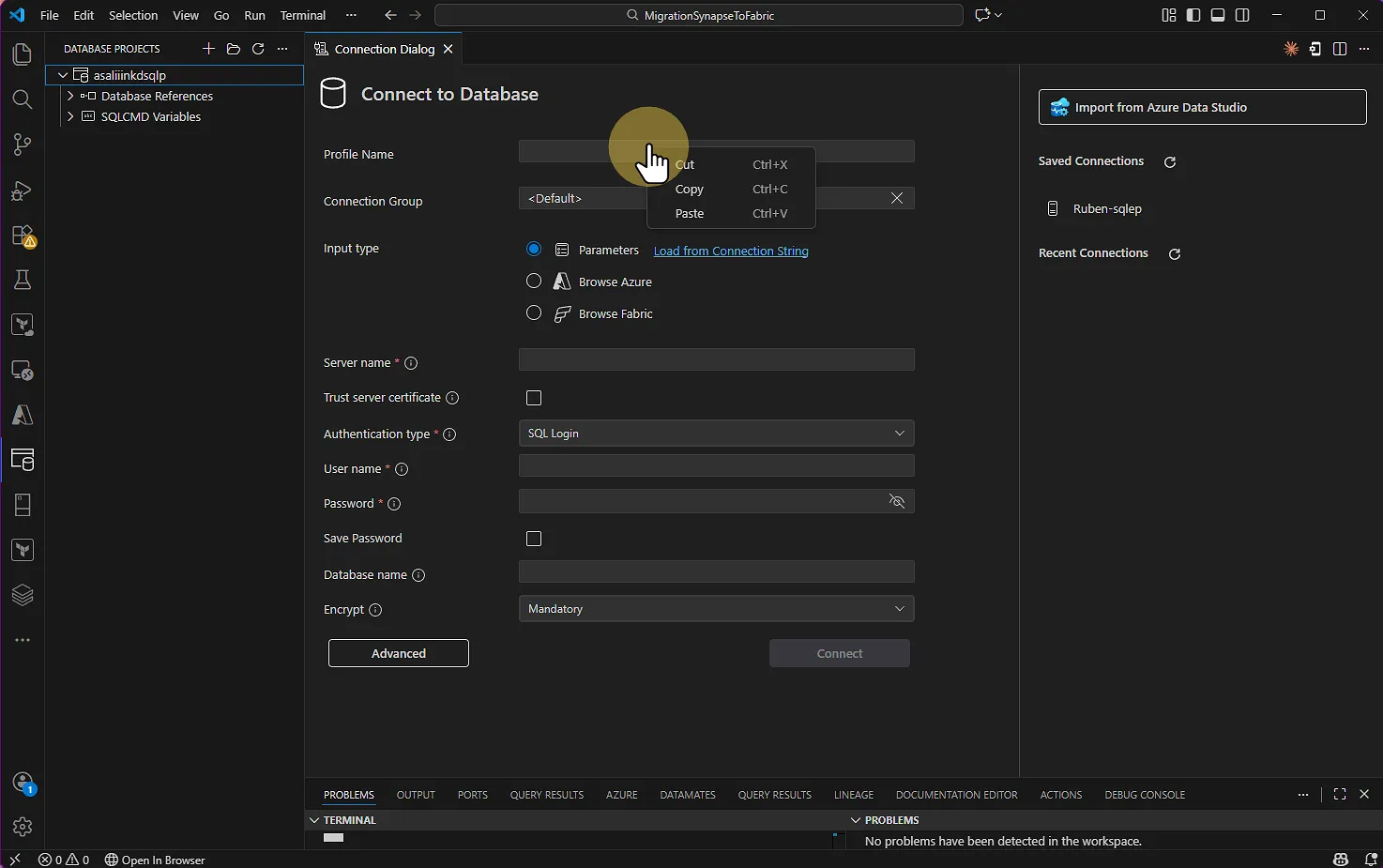
Une fois la connexion établie, retournez dans Database Projects et relancez la mise à jour en l'utilisant(Sélectionnez votre chaine de connexion puis votre pool dédié).
Vous aurez alors le choix entre :
View changes in schema compare : Pour visualiser les différences
Apply all changes : Pour tout importer directement
Sélectionnez Apply all changes pour mettre à jour l'intégralité du projet local à partir de la base de données distante.
Étape 3 : Vérifier l'import
Après quelques instants, tout est récupéré. Vous allez constater que l'ensemble de vos objets est maintenant en local :
Tous vos utilisateurs
Tous vos schémas
Toutes vos tables
Toutes vos vues
Toutes vos procédures stockées
Toutes vos fonctions
Le tout organisé dans une arborescence de répertoires claire et exploitable.
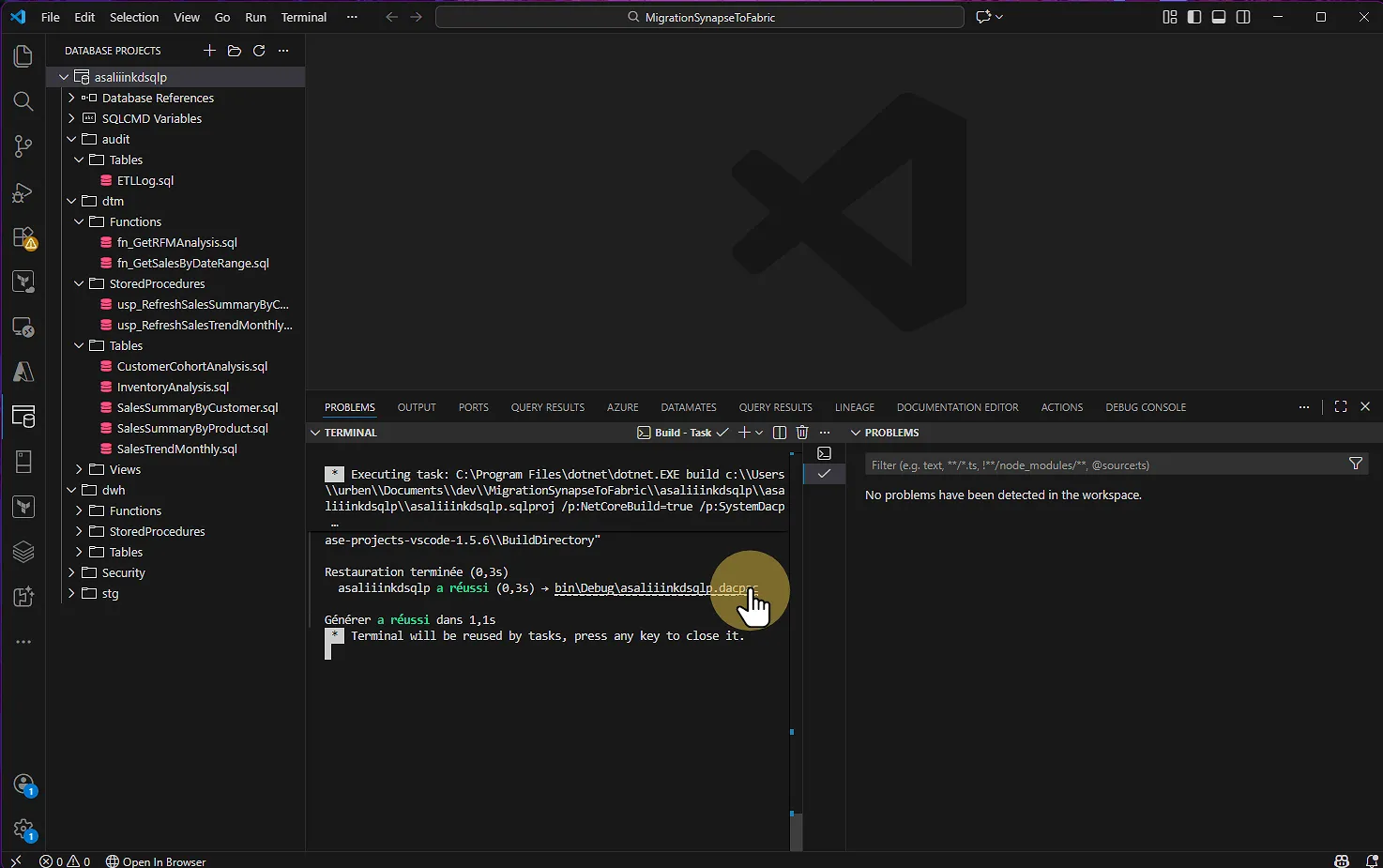
Étape 4 : Générer le DACPAC
À partir de ce moment, il faut générer le fichier DACPAC qui servira à la migration vers Fabric.
Faites un clic droit sur votre projet
Sélectionnez Build
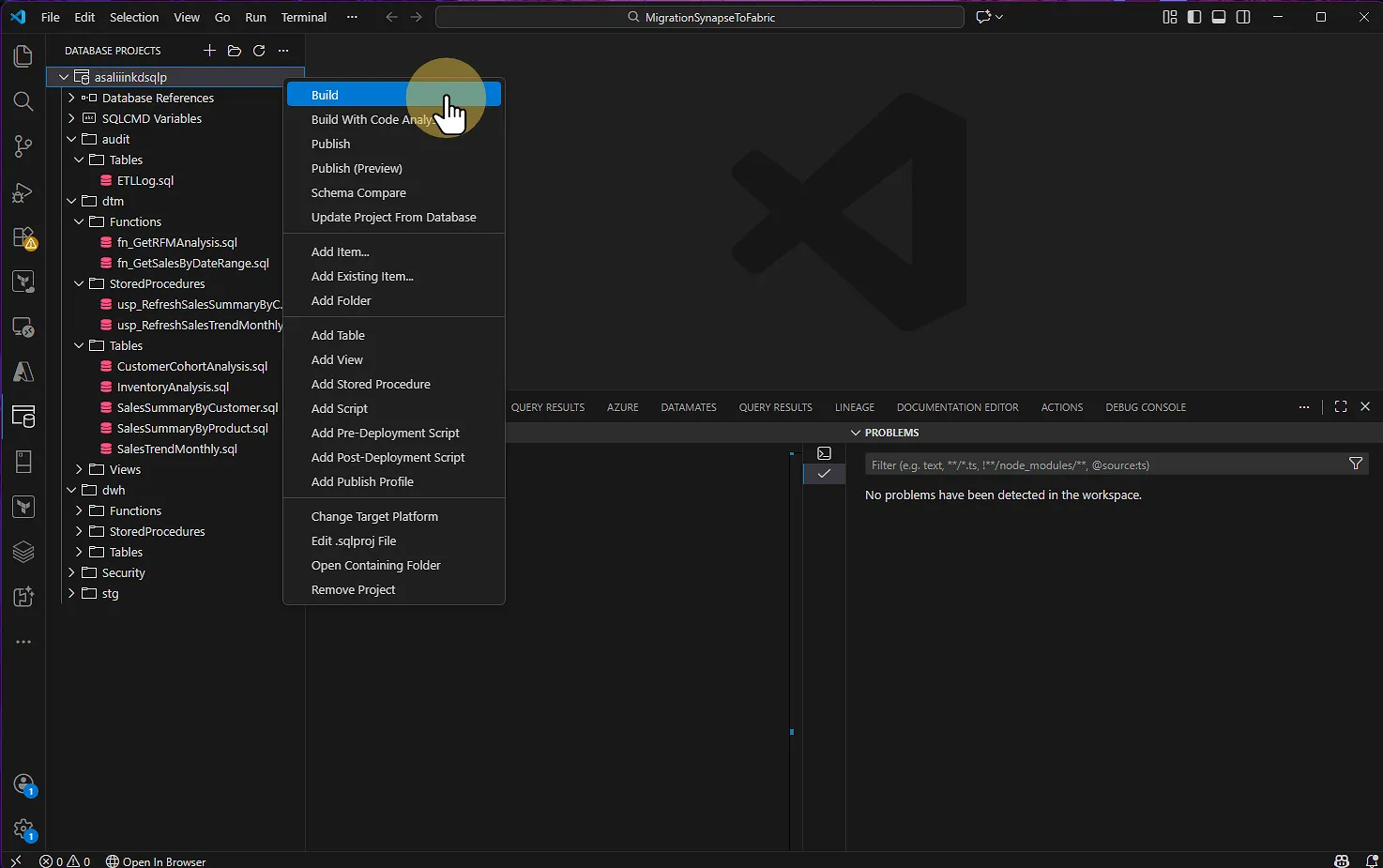
VS CODE : Database projects > Build
Vous verrez dans le terminal un message confirmant le succès ou l'échec du build.
# Commentaires En français
<nom de projet> a réussi (0,3s) → bin\Debug\<nom de projet>.dacpac
Générer a réussi dans 1,1s
Le fichier DACPAC se trouve par défaut dans : bin\Debug\votreprojet.dacpac
📌 Important : Le DACPAC contient uniquement le schéma (DDL) — tables, vues, procédures stockées, fonctions, rôles... — mais jamais les données. C'est un point crucial à comprendre pour la suite.
📚 Ressource : What are SQL Database Projects?
Étape 5 : Lancer l'assistant de migration dans Fabric - (Phase 1)
Direction Microsoft Fabric !
Connectez-vous à app.fabric.microsoft.com
Sélectionnez votre espace de travail
Cliquez sur Migrate (Dans le bandeau du haut)
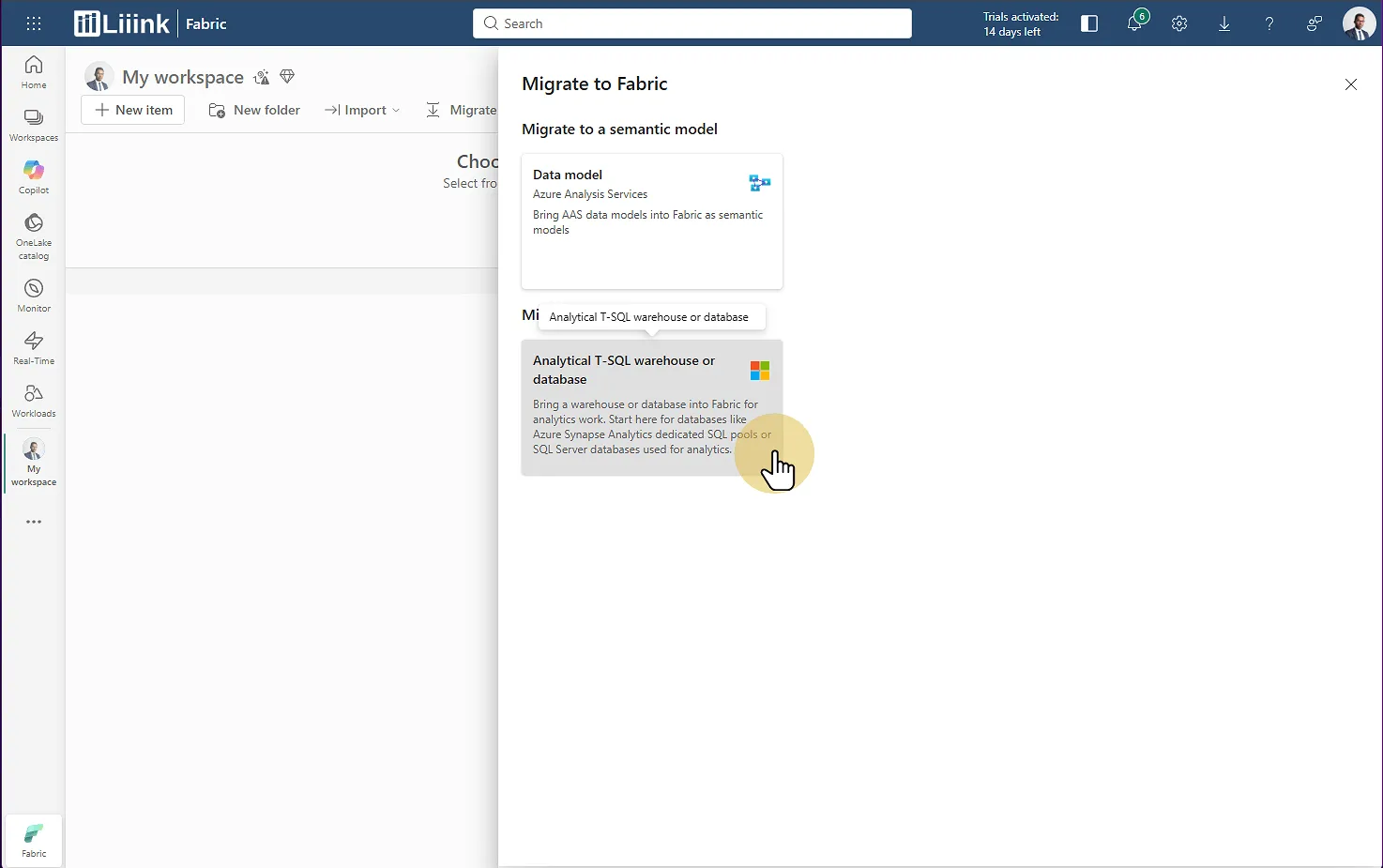
Fabric : Migrate > Analytical T-SQL Warehouse or Database Choisissez Analytical T-SQL Warehouse or Database
Sélectionnez le deuxième choix pour créer un Warehouse
Étape 6 : Charger le DACPAC
Un modal s'ouvre. Naviguez jusqu'à l'étape où l'on vous demande votre source (Set the source).
Uploadez votre fichier
.dacpacprécédemment généré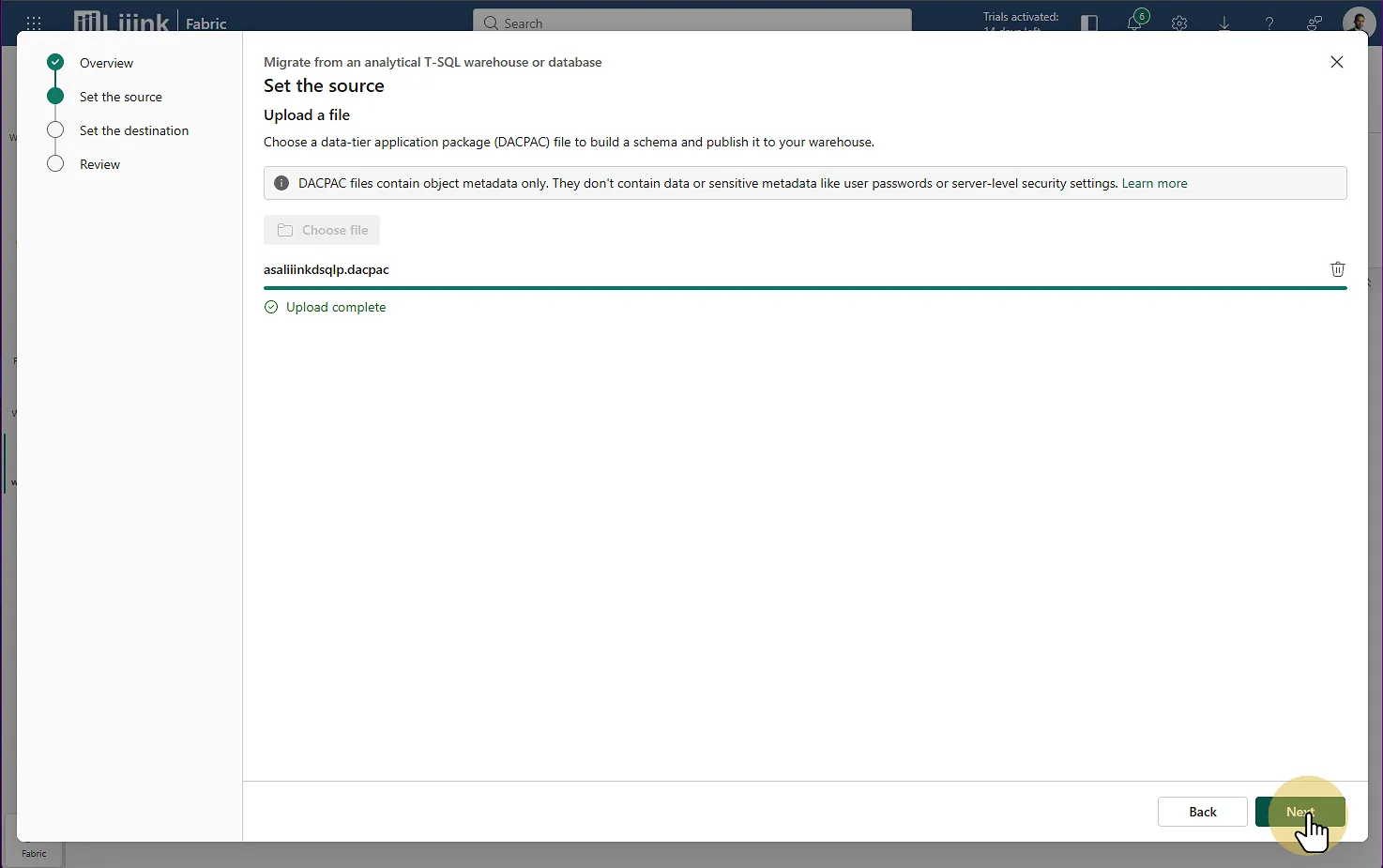
Fabric : Migrate > Upload DACPAC file Sélectionnez votre workspace de destination
Indiquez le nom de votre nouveau warehouse
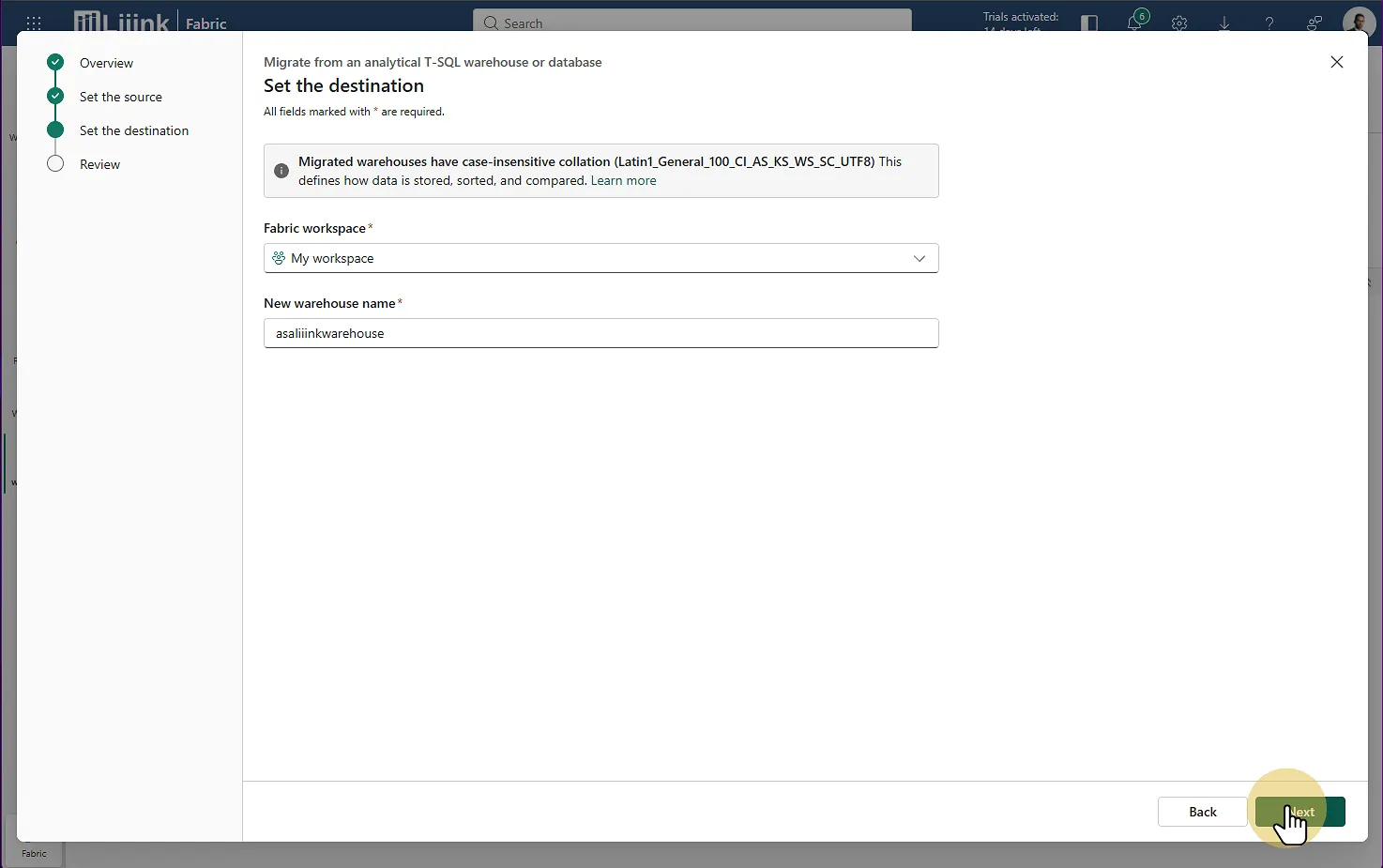
Fabric : Migrate > Set the destination > Choisir le workspace > Définir le nom du warehouse
Cliquez sur Next pour lancer l'assistant de migration.
Étape 7 : Analyser les résultats de migration - (Phase 2)
L'assistant de migration s'ouvre et vous présente un résumé :
✅ Nombre d'objets correctement migrés
⚠️ Nombre d'objets à corriger
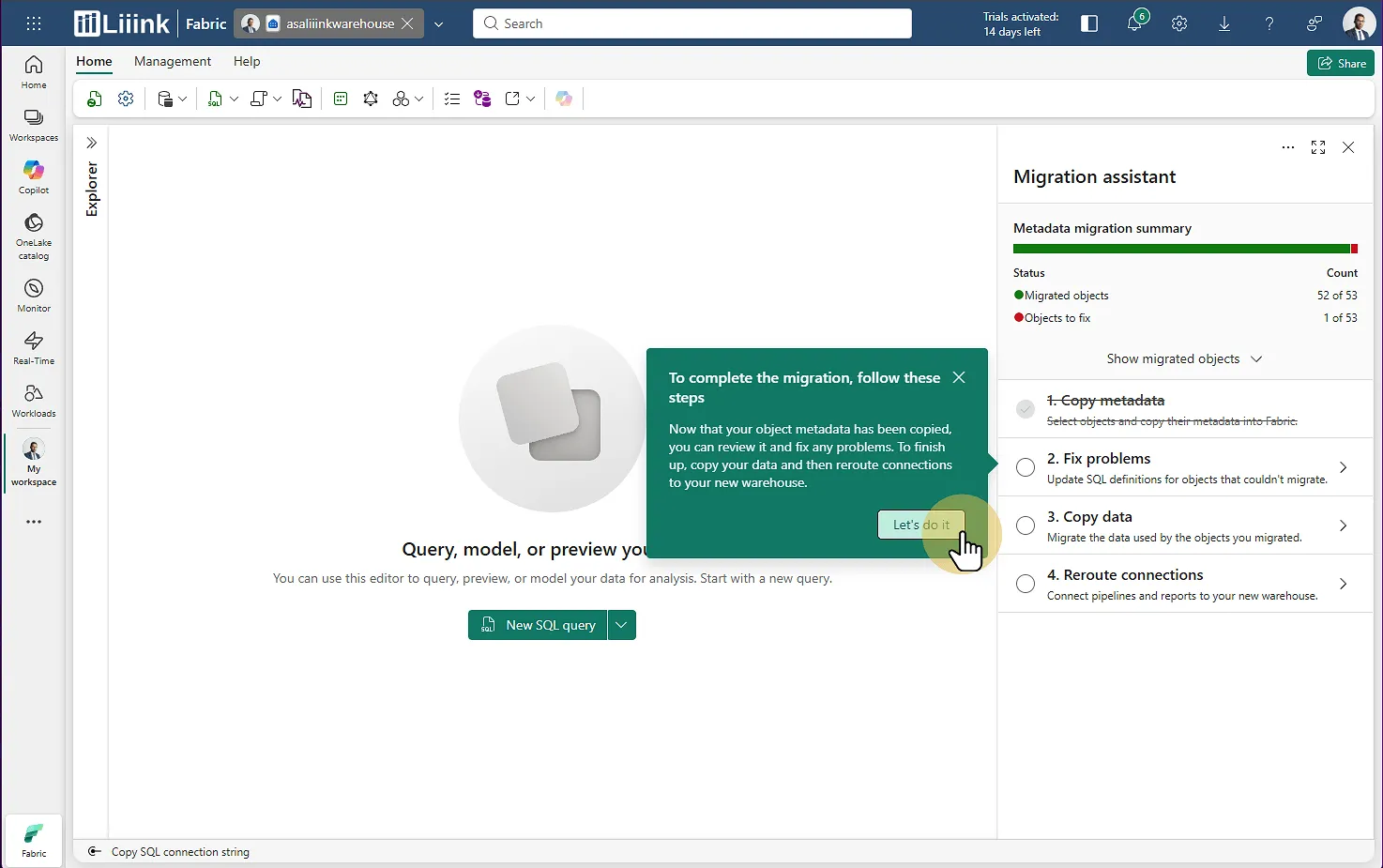
Étape 8 : Corriger les problèmes
Dans mon exemple, j'avais un souci sur un rôle d'utilisateur. En cliquant sur Fix Problems, je peux voir les éléments à corriger.
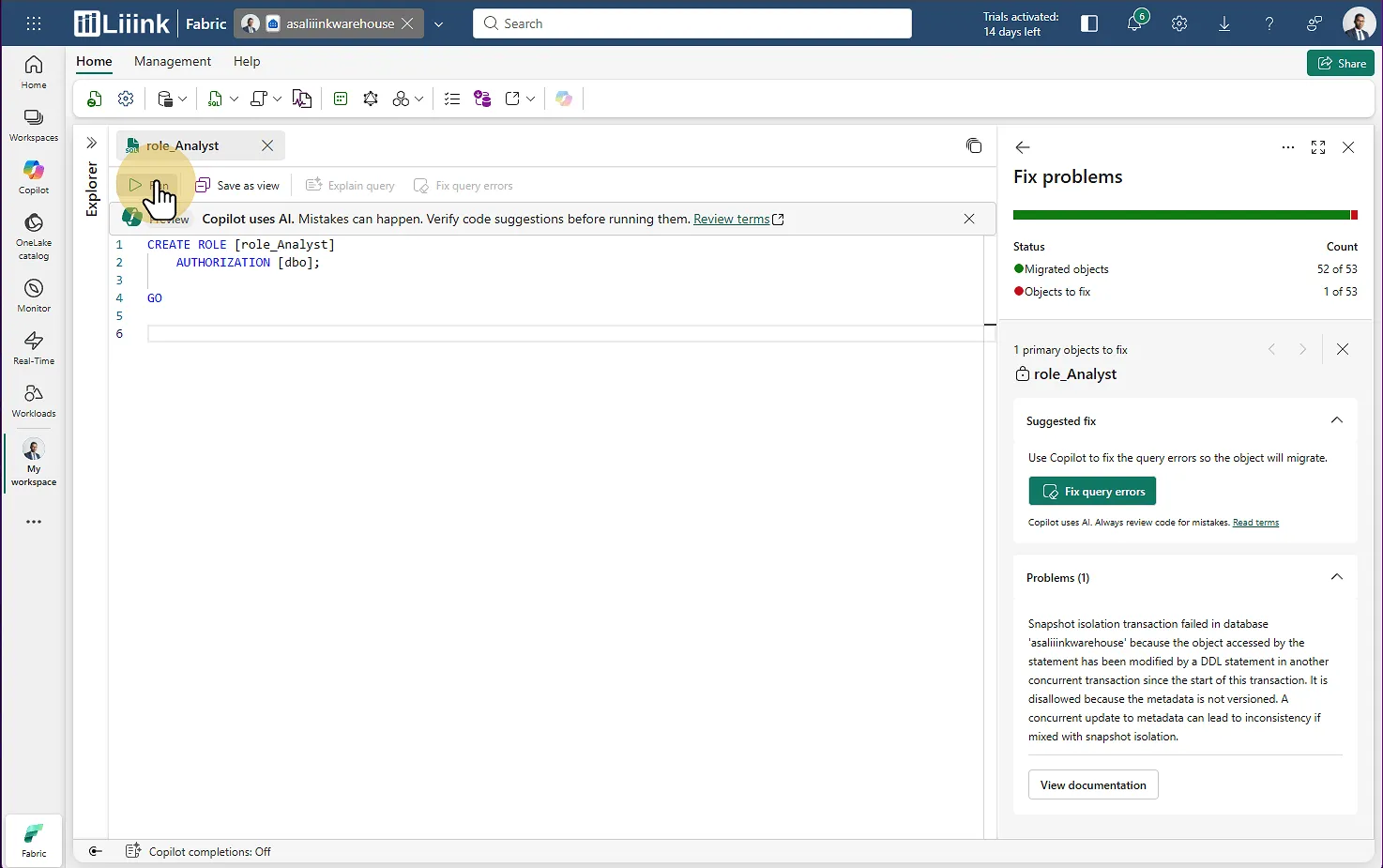
Exemple : la création du rôle "Analyste" a échoué, il y a eu un problème de concurrence de transactions qui a empêché l'exécution de l'instruction de création de rôle.
Il suffit d'exécuter la requête à nouveau pour valider la correction.
Et voilà, c'est corrigé : 53 objets migrés sur 53.
Points d'attention fréquents
Vous pourriez rencontrer d'autres incompatibilités :
Problème | Solution |
|---|---|
| Indiquer la précision : |
| Utiliser |
Utilisateurs SQL Server | Migrer vers Microsoft Entra ID |
Fonctions scalaires non-inlineable | Réécrire en fonctions inlineables |
Tables externes | Non supportées, à retravailler |
💡 Bonne nouvelle : Microsoft a fait d'énormes progrès ! Il y a quelques mois, on ne pouvait pas migrer de CTE, pas d'instructions MERGE... Aujourd'hui, c'est beaucoup plus smooth. Chapeau Microsoft !
📚 Ressources : Fabric Migration Assistant | Limitations Fabric Warehouse
Étape 9 : Migrer les données - (Phase 3)
Une fois les problèmes de schéma corrigés, il faut s'attaquer aux données.
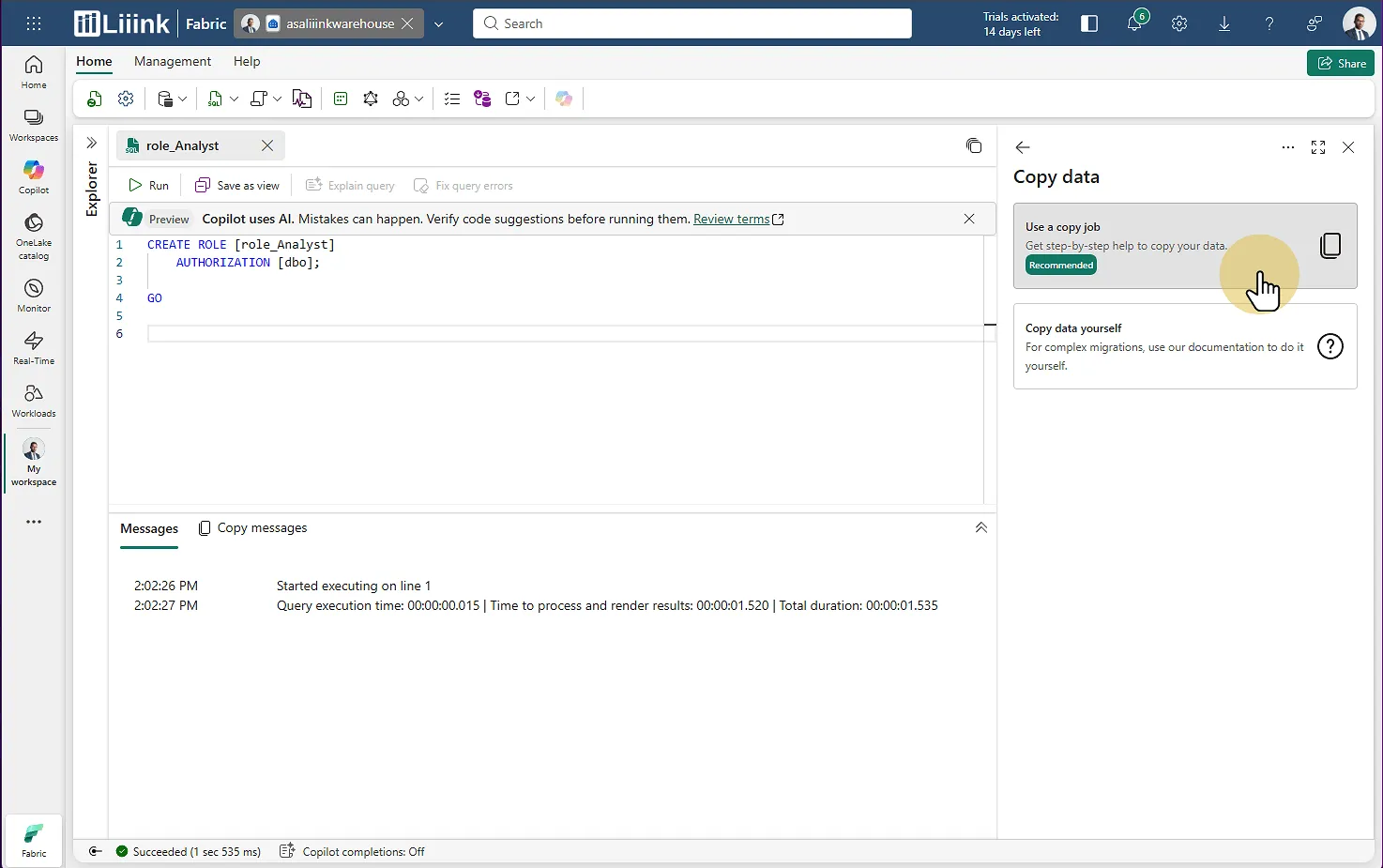
L'outil vous propose deux possibilités :
Option 1 : Copy Jobs (recommandé pour les cas simples)
C'est une sorte de wizard qui vous guide dans la copie de données. Simple et efficace si :
Vous avez du 1 pour 1 à faire
Pas de transformation complexe
Pas d'initialisation de données spécifique
C'est ce qu'on choisit pour notre cas trivial.
Option 2 : Copie manuelle (pour les cas complexes)
Dès lors que vous devez :
Préserver une logique métier
Transférer des Surrogate Keys (SK)
Maintenir l'intégrité référentielle sur plusieurs tables
Gérer des SCD Type 2
Préserver des clés étrangères
C'est là où ça se corse. Vous devrez copier la donnée vous-même avec une approche personnalisée :
Pipelines Fabric (Data Factory)
Dataflow Gen2
CETAS vers Data Lake puis Shortcut
Notebooks Spark
⚠️ Attention : Pour les migrations de grande ampleur avec des modèles relationnels complexes, contraintes d'intégrité poussées et gestion des identités critiques, il faudra bien penser la manière d'ingérer vos données et préserver vos ID, SK et relations.
Étape 10 : Exécuter le Copy Job
Le Copy Job se lance comme un wizard :
Source : Sélectionnez votre pool dédié Synapse
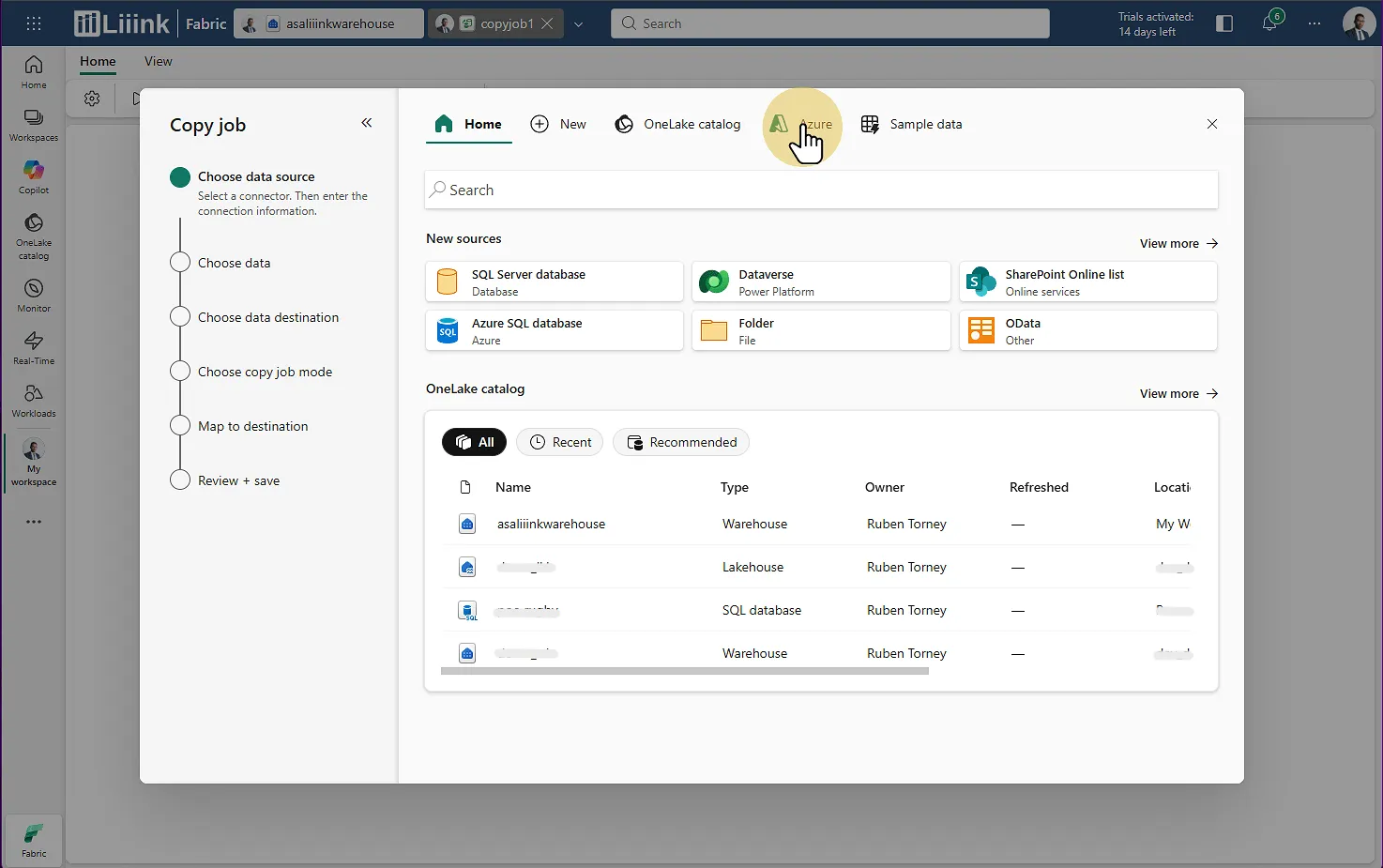
Fabric : Migrate > Migration assistant > Phase 3 : Copy Data > Choisir la source Tables : Choisissez l'ensemble des tables à remonter
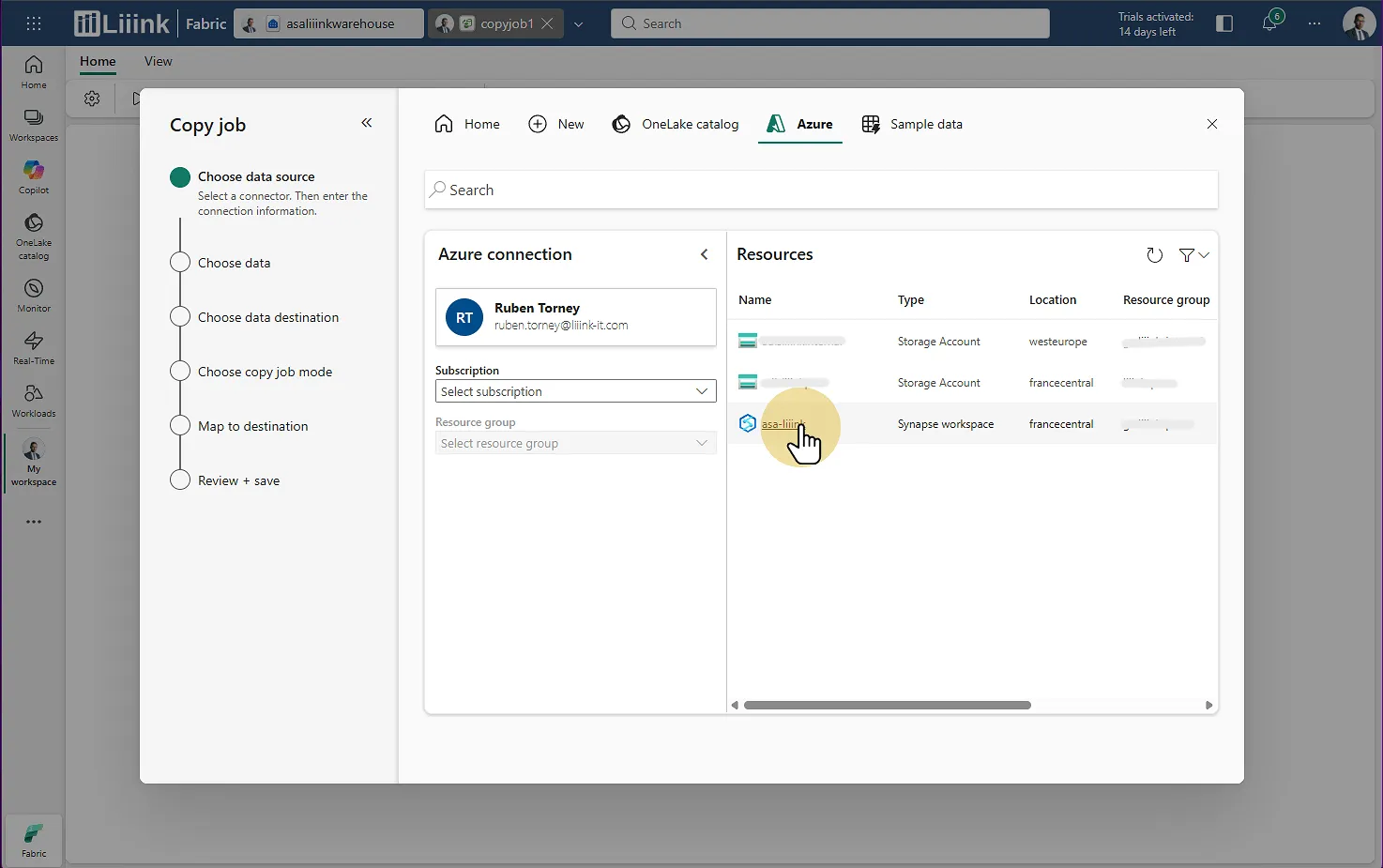
Fabric : Migrate > Migration assistant > Phase 3 : Copy Data > Choisir le pool dédié 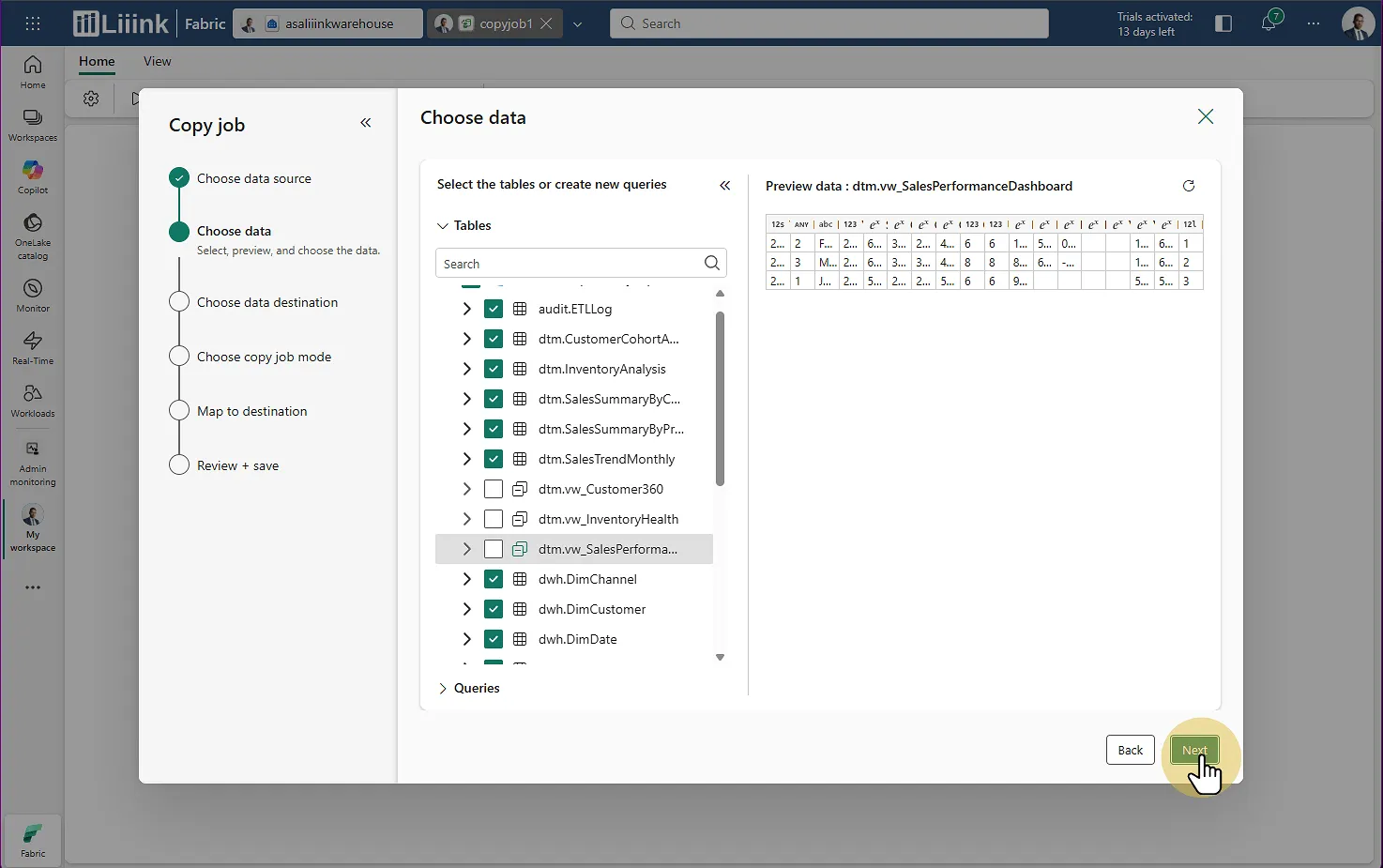
Fabric : Migrate > Migration assistant > Phase 3 : Copy Data > Sélectionner les tables Destination : Sélectionnez votre nouveau warehouse Fabric
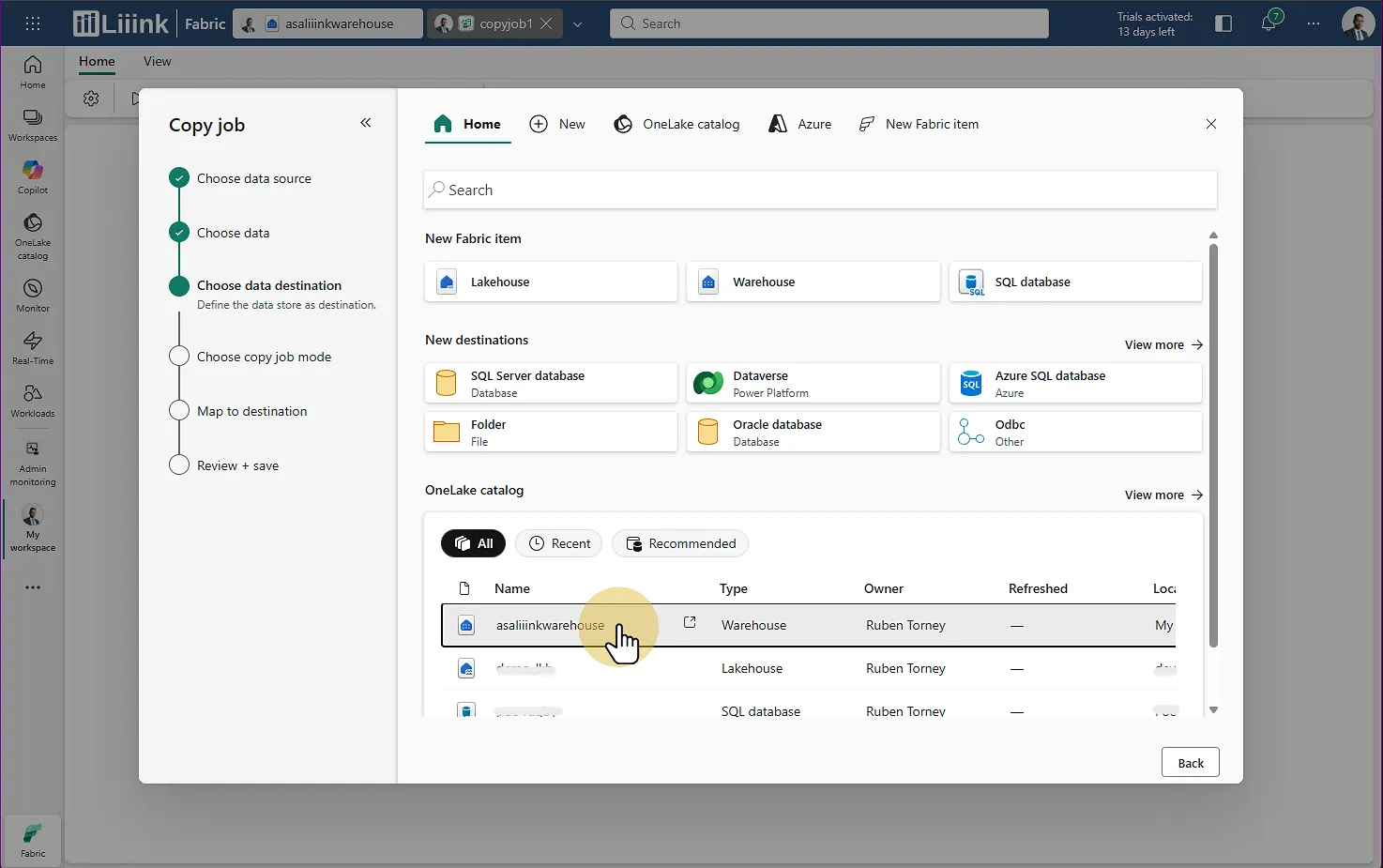
Fabric : Migrate > Migration assistant > Phase 3 : Copy Data > Choisir la destination > Sélectionner le warehouse 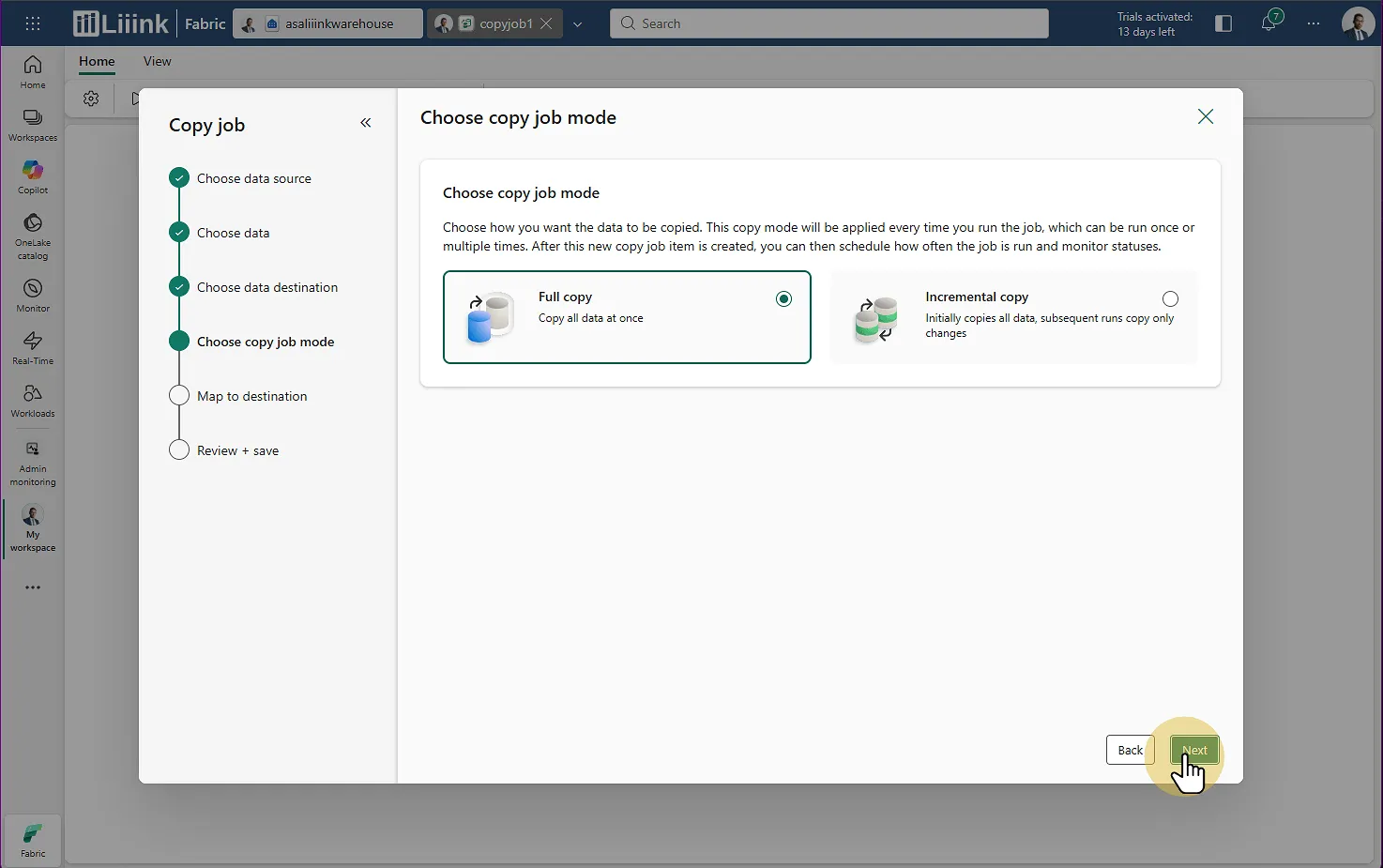
Fabric : Migrate > Migration assistant > Phase 3 : Copy Data > Choisir le type de chargement (Full Copy pour ce cas) Mapping : Contrôlez le mapping si nécessaire (ici c'est du 1 pour 1)
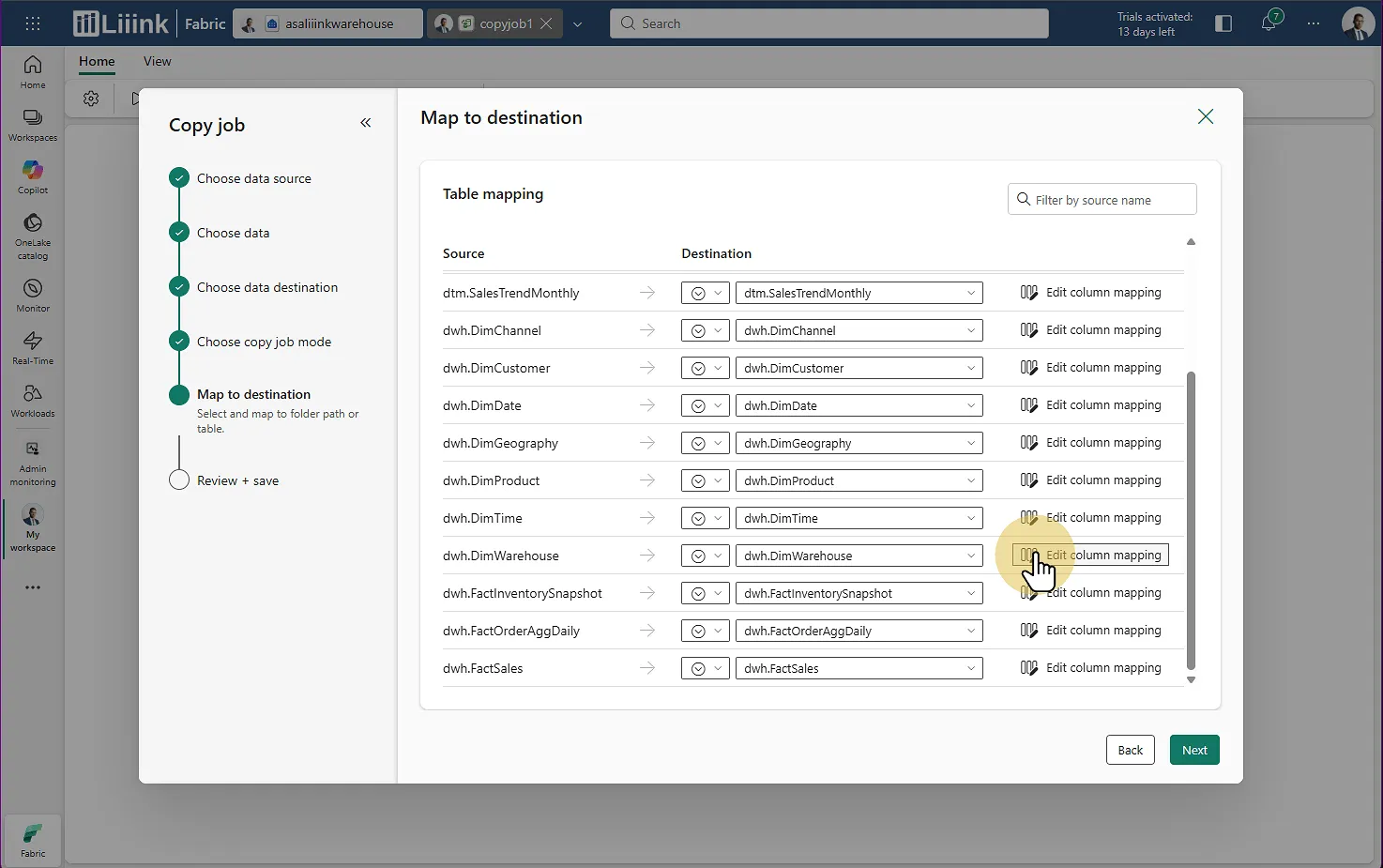
Fabric : Migrate > Migration assistant > Phase 3 : Copy Data > Contrôler le mapping : source <> destiantion
C'est simple, c'est bien pensé, et il n'y a pas de grande difficulté.
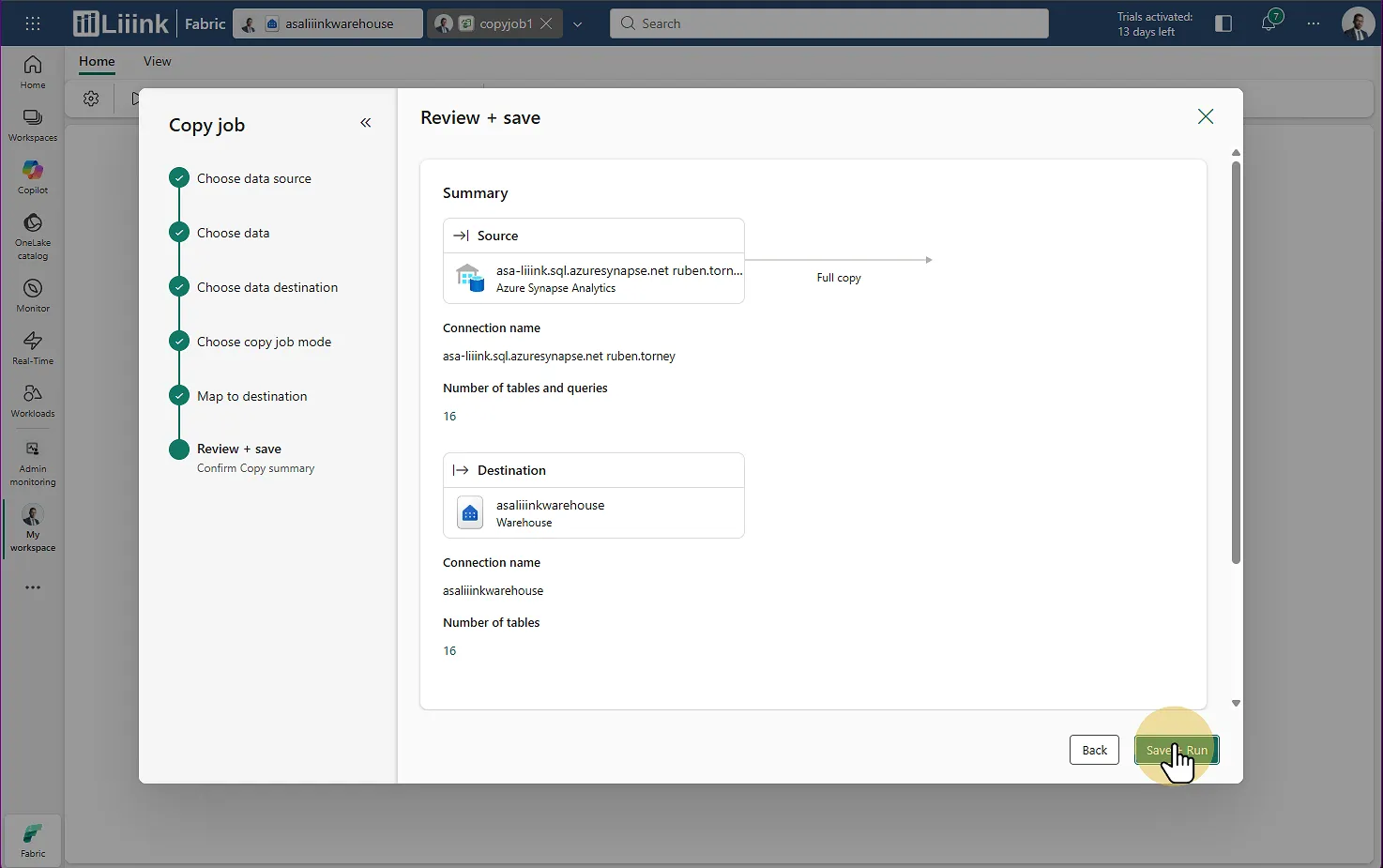
Étape 11 : Lancer et surveiller le chargement
Une fois le wizard terminé, un pipeline apparaît dans votre workspace.
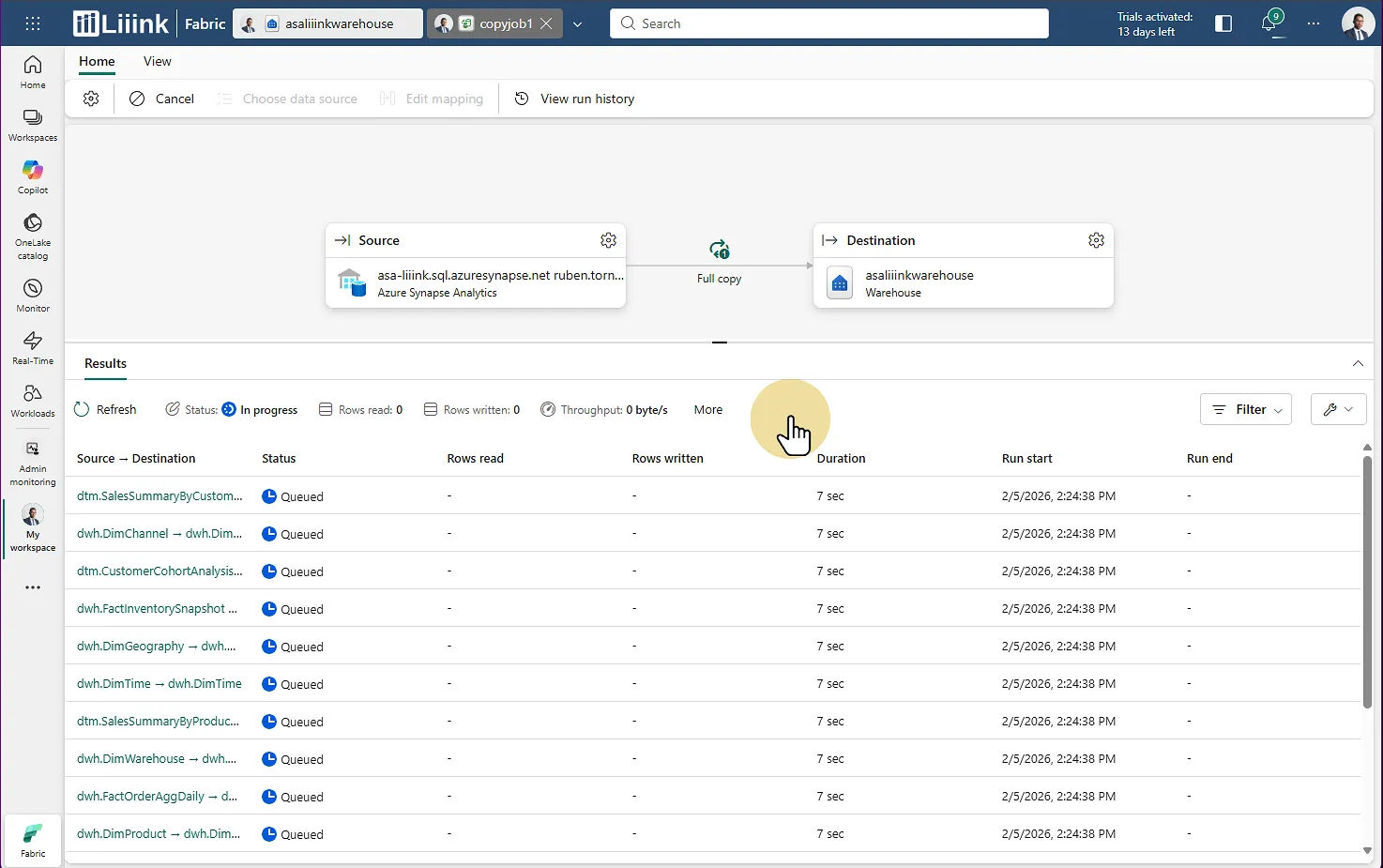
Lancez le pipeline (Copy job)
Observez le chargement successif de chacune des tables
Étape 12 : Valider la migration
Une fois le chargement terminé, allez voir votre warehouse et consultez vos données.
Si le travail a bien été fait, vous retrouverez l'intégralité de vos données dans votre warehouse Fabric.
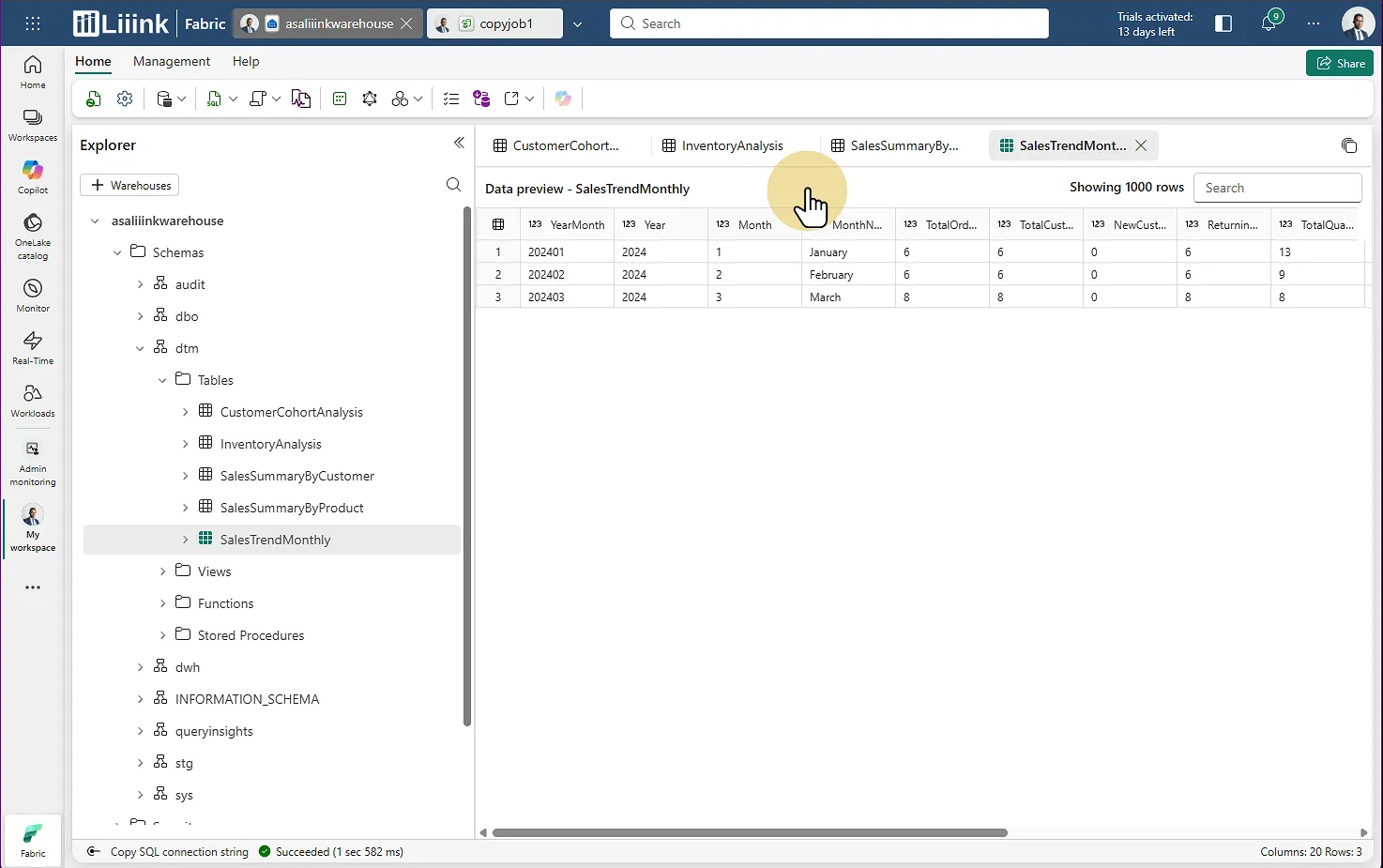
Post-migration : Les étapes à ne pas oublier
La migration technique est terminée, mais le travail ne s'arrête pas là !
1. Reconnecter les rapports Power BI (ou autre outil)
Tous vos rapports pointaient sur le pool dédié Synapse. Il faut maintenant les faire pointer sur le warehouse Fabric.
Modifier les chaînes de connexion
Tester les rafraîchissements
Valider les performances
2. Réorchestrer les jobs SQL
Si vous utilisez du T-SQL pour vos ETL/ELT :
Revoir l'orchestration de vos jobs SQL
Adapter les procédures stockées si nécessaire
Mettre à jour les dépendances
3. Adapter les notebooks
Si vous faisiez de la transformation sur votre pool dédié avec des notebooks :
Adapter le code pour Fabric Warehouse
Mettre à jour les connexions Spark
Tester les performances
Conclusion
Cette migration est plutôt simple à réaliser et ne prend que quelques minutes si :
Vous avez un petit pool dédié
Vous n'avez pas de logique métier complexe
Vos tables sont en 1 pour 1
Vos datamarts sont de taille raisonnable
Dans ces cas-là, la migration se fait rapidement, sans trop d'efforts.
Mais attention pour les migrations de plus grande ampleur :
Modèles relationnels complexes
Contraintes d'intégrité élaborées
Gestion des identités critiques
Clés de SCD Type 2
Dans ces situations, il faudra passer par une approche moins automatisée et bien réfléchir à :
L'initialisation des données
La préservation de l'intégrité
La cohérence globale du data warehouse
J'espère que ce guide pas à pas vous aidera si vous avez la moindre question ou remarque, ou si vous avez besoin de discuter au sujet d'une migration. N'hésitez pas à nous contacter.